
بسیاری از گیمرهای خوره حوزه PC به شدت منتظر نسل جدید کارتهای گرافیک دو شرکت انویدیا و AMD هستند که قرار است با دو معماری Ada Lovelace و RDNA 3 روانه بازار شوند. به تازگی و البته یک بار دیگر، مشخصات کارتهای گرافیک Radeon RX 7900 XT و GeForce RTX 4090 لو رفته که میتواند اطلاعات بسیار جالبی از این دو کارت را در اختیار علاقهمندان قرار دهد.
اگرچه یک کارت گرافیک امروزی پرچمدار نیز به راحتی میتواند از پس اجرای سنگینترین بازیها یا فعالیتهای گرافیکی برآید ولی نیاز روز افزون به افزایش قدرت پردازش گرافیکی، نیازی است که هیچگاه به پایان نرسیده و همواره مطالبهگر بیشتر و بیشترهاست.
تا پیش از این چندین مرتبه اطلاعات مربوط به کارتهای گرافیک برپایه پردازندههای Navi 31 و AD102 از دو شرکت AMD و Nvidia منتشر شده و اطلاعات کاربران از آنها چندان هم اندک نیست، اما دور جدید اطلاعات لو رفته، این پردازندههای تشنه توان بالا و بالاتر را بیش از پیش به کاربران معرفی میکند.
در حالی که NVIDIA با معماری Ada Lovelace خود رویکردی یکپارچه را مد نظر قرار داده، AMD از طراحی کامل MCM استفاده می کند که پیش از این با رونمایی از سری Aldebaran MI200 آنها را وارد حوزه رقابت کرده است. AMD اکنون از همان فناوری MCM برای پردازندههای گرافیکی مخصوص مصرفکننده و بازی استفاده خواهد کرد.

مشخصات کامل Navi 31
همانطور که عنوان شد در دور جدید اطلاعات لو رفته در مورد تراشههای فوق اطلاعات جالبی منتشر شده است. از قبل میدانیم که پردازنده گرافیکی AMD Navi 31 به عنوان یک تراشه پرچمدار RDNA 3 میتوان نسل بعدی Radeon RX 7900 XT را قدرت بخشیده و افقی جدید در این حوزه ایجاد کند.
شنیدهها حاکی از آن هستند که AMD قصد کنار گذاشتن واحدهای پردازشی یا همان CUها و جایگزین کردن آنها با WGPها یا پردازشگرهای گروه کاری (Work Group Processors) در پردازندههای گرافیکی نسل بعدی RDNA 3 دارد.
در نقطه مقابل Navi 31 یک پردازنده گرافیکی MCM است که از دو IP و یک GCD (Graphics Core Die) بر پایه فناوری ساخت 5 نانومتری و البته MCD (Multi-Cache Die) بر پایه فناوری 6 نانومتری TSMC استفاده میکند.
پیکربندی Navi 31 نشان میدهد که در آن از دو GCD و یک MCD استفاده میشود که هر GCD سه موتور سایهزنی (در مجموع 6 موتور) دارد که هر موتور نیز از دو آرایه سایه زنی استفاده میکند. در این میان هر آرایه سایهزنی از 5 واحد WGP استفاده میکند که WGP نیز شامل 8 واحد SIMD32 با 32 واحد ALU خواهد بود. در نهایت میتوان گفت این واحدهای SIMD32 با ترکیب یکدیگر تعداد 7،680 هسته در هر GCD را شکل میدهند و از آنجایی که ساختار کلی شامل دو GCD است میتوان گفت که در هر تراشه پردازشگر گرافیکی Navi 31 با 15،360 هسته پردازشی روبرو خواهیم بود.
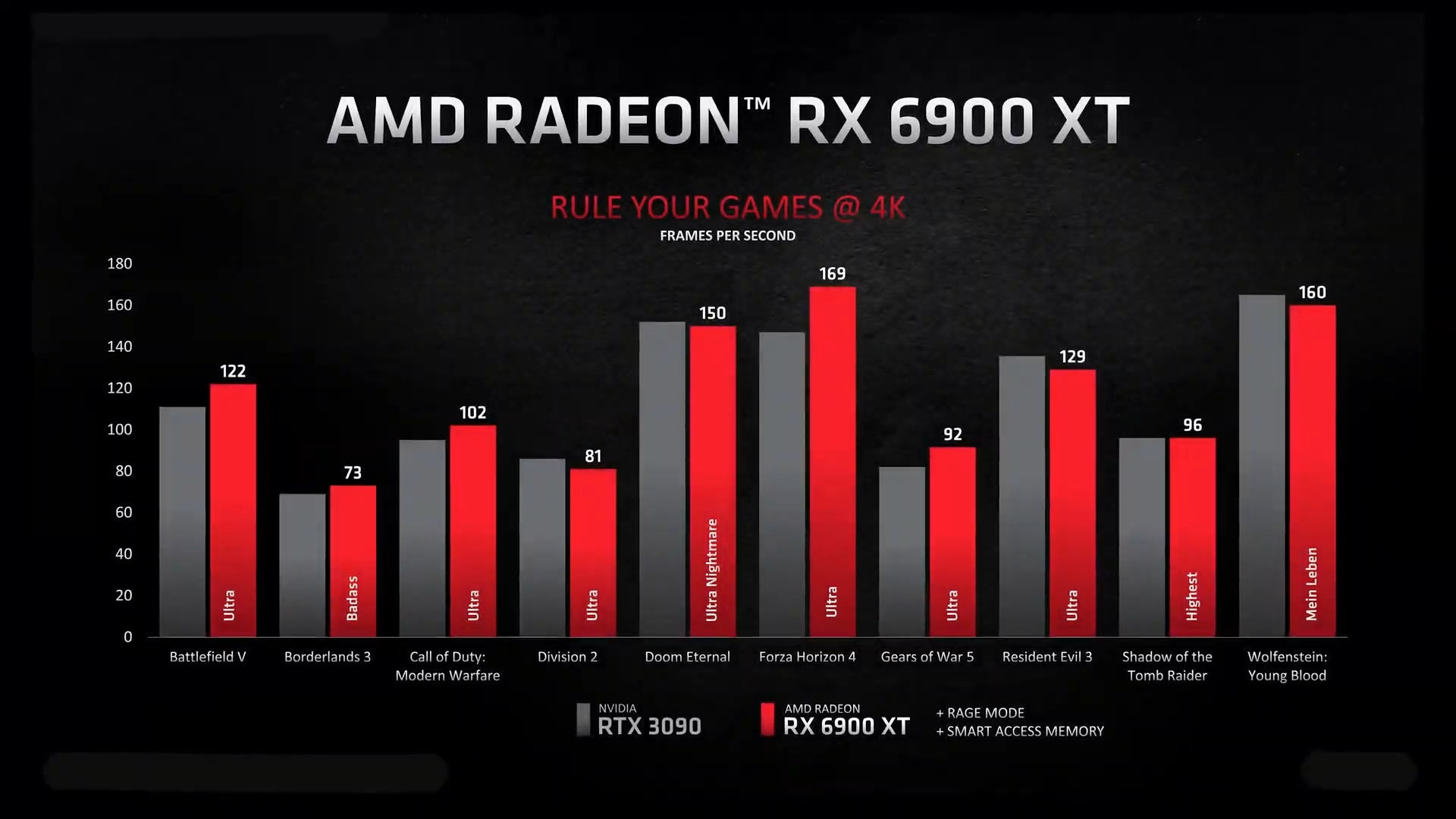
از دیدگاه پردازشی، انتظار میرود سرعت کلاک GPU بین 2.4 تا 2.5 گیگاهرتز باشد که عملکرد تئوری 75 ترافلاپس (FP32) را نتیجه میدهند که در مقابل کارت گرافیک Radeon RX 6900 XT تا 226 درصد بیشتر است.
واحد MCD در Navi 31 با استفاده از یک واحد ارتباط داخلی Infinity Fabric به هر کدام از واحدهای GCD متصل میشود که از حافظه Infinity Cache به میزان 256 یا 512 گیگابایت استفاده خواهد کرد. هر GPU باید از 4 ارتباط داخلی حافظه 32 بیتی نیز پشتیبانی کند. در نهایت برای یک گذرگاه 256 بیتی، تعداد 3 کنترل کننده حافظه 32 بیتی مورد نیاز خواهد بود. باید به این موضوع نیز اشاره کرد که این کارت از حافظههای گرافیک GDDR6 به اندازه 32 گیگابایت که در سرعت 18 گیگابیت بر ثانیه کار کرده و میتوانند پهنای باندی برابر با 576 گیگابایت بر ثانیه را ایجاد کنند استفاده مینمایند.
شایعه دیگری که اخیراً منتشر شد نشان می دهد که AMD از فناوری 3D Infinity Cache در سری RDNA 3 خود استفاده خواهد کرد که کش جدید را در پشتههای عمودی روی GPUها ادغام میکند، مشابه اینکه تراشه های Vermeer-X کش L3 را روی CCD قرار می دهند.

مشخصات کامل AD102
بر اساس شایعات قبلی، زمزمه هایی وجود دارد مبنی بر اینکه NVIDIA از لیتوگرافی N5 (5 نانومتری) شرکت TSMC برای پردازنده های گرافیکی Ada Lovelace خود استفاده میکند. این لیتوگرافی شامل SKU AD102 نیز میشود که یک طراحی کاملا یکپارچه خواهد بود. در جدیدترین اطلاعات منتشر شده که در مورد پیکربندیهای GPU خاص صحبت میکند، گفته میشود که پردازنده گرافیکی AD102 دارای سرعت کلاک تا ۲.۵ گیگاهرتز (۲.۳ گیگاهرتز بوست متوسط) خواهد بود.
همچنین به این نکته نیز اشاره شده که سرعت کلاک GPU در AD102 میتواند برابر با 2.3 گیگاهرتز یا حتی بالاتر نیز باشد که در نتیجه میتوان برای درک مشخصات اعلام شده دیگر، آن را به عنوان یک مقدار ثابت، مقبول دانست.

به نظر می رسد NVIDIA AD102 "ADA GPU" دارای 18،432 هسته CUDA بر اساس مشخصات اولیه (که میتواند تغییر کند) است که در 144 واحد SM قرار گرفتهاند. این مقدار تقریباً دو برابر هستههای موجود در معماری Ampere است که پیش از آن یک گام بزرگ در مقابل معماری Turing به حساب میآمد. سرعت کلاک 2.3-2.5 گیگاهرتز همچنین موجب ارائه توان پردازشی معادل 85 تا 92 TFLOPs برای عملیات FP32 خواهد شد. این مقدار نیز به نوبه خود دو برابر توان پردازش FP32 کارت گرافیک RTX 3090 خواهد بود که از توان پردازشی 36 ترافلاپسی FP32 برخوردار است.
اینکه انویدیا با کارتهای نسل بعدی میتواند توان پردازشی را تا 150 درصد افزایش دهد اتفاق هیجانانگیزی خواهد بود، اگر بدانیم که در حال حاضر نیز Ampere در برخی کارتهای گرافیک موجب ارتقای قابل توجهی نسبت به نسل قبلی در توان پردازشی FP32 شده است.
از قبل میدانیم که RTX3090 توان پردازشی 36 ترافلاپس و RTX 2080 Ti توان پردازشی 13 ترافلاپس را در دو نسل معماریهای پردازشگر گرافیکی انویدیا ارائه نمودهاند که نشاندهنده ارتقایی بیش از 150 درصد است ولی در عملکرد دنیای واقعی باید گفت که به صورت متوسط، یک کارت RTX 3090 توان پردازشی بین 50 تا 60 درصد بیشتر از RTX 2080 Ti ارائه میکند.

به همین خاطر نکتهای که نباید از آن غافل شویم این است که توان پردازش گیمینگ نهایی آن چیزی نخواهد بود که در اعداد و ارقام FP32 مورد اشاره قرار گرفت. مضاف بر این هنوز نمیتوان به حداکثر فرکانس کلاک تراشه مطمئن بود و باید بیشتر منتظر بمانیم و ببینیم در نهایت انویدیا چه تدبیری برای این رقم مهم در نظر خواهد گرفت.
نکته دیگری که لیکستر به آن اشاره کرده این است که انویدیا قصد دارد در کارتهای گرافیک سری پرچمدار RTX 40 خود از باس 384 بیتی استفاده کند که مشابه RTX 3090 است. ویژگی جالب دیگر این است که لیکستر معروف منتشر کننده این اطلاعات اعلام نموده که NVIDIA از حافظههای G6X استفاده خواهد نمود و نمیخواهد به استاندارد نسل بعدی معرفی شده در این زمینه (مثلاً GDDR7) مهاجرت کند.
این کارت میتواند 24 گیگابایت حافظه گرافیکی داشته باشد که پیشبینی میشود از نوع حافظه DRAM 16 گیگابیت یک طرفه یا ماژولهای DRAM 8 گیگابایت دوطرفه باشد.

پردازندههای گرافیکی NVIDIA Ada Lovelace نسل بعدی کارتهای گرافیک GeForce RTX 40 را تامین میکنند که با کارتهای گرافیک سری Radeon RX 7000 مبتنی بر RDNA 3 AMD رقابت میکنند. البته هنوز برخی گمانه زنی ها در مورد استفاده از MCM توسط NVIDIA وجود دارد. در نظر داشته باشید که پردازنده گرافیکی Hopper که عمدتاً بخش Datacenter و AI را هدف قرار میدهد، ظاهراً به زودی تولید می شود و دارای معماری MCM خواهد بود.
در آخر باید مجدداً یادآور شویم که NVIDIA از طراحی MCM بر روی پردازندههای گرافیکی Ada Lovelace خود استفاده نخواهد کرد، بنابراین این شرکت همچنان طراحی سنتی یکپارچه را حفظ نموده و ظاهراً تغییرات بزرگ را به نسلهای بعدی موکول خواهد کرد.







 هر دفه یه بامبولی در میارن یب گیمر بدبخت رو خلی کنن . بعد تبلیغت رو میبینه صحبت از 8 کی گیمینگ تستایه یوتیوب رو میبینه صحبت از 4 کی میگیره میاد خونه میبینه به زور باهاش 2 کی رو مک س بازی میکنه . دیگه فریم ریت بالایه 60 که هیچی اخرشم گرافیک میخره حرف از سی پی یو میشه سی پی یو میگیره حرف از رم میشه . کلایه طوری باید جیب گیمر بد بخت رو بزنن
هر دفه یه بامبولی در میارن یب گیمر بدبخت رو خلی کنن . بعد تبلیغت رو میبینه صحبت از 8 کی گیمینگ تستایه یوتیوب رو میبینه صحبت از 4 کی میگیره میاد خونه میبینه به زور باهاش 2 کی رو مک س بازی میکنه . دیگه فریم ریت بالایه 60 که هیچی اخرشم گرافیک میخره حرف از سی پی یو میشه سی پی یو میگیره حرف از رم میشه . کلایه طوری باید جیب گیمر بد بخت رو بزنن









نظر خود را اضافه کنید.
برای ارسال نظر وارد شوید
ارسال نظر بدون عضویت در سایت