
برای اینکه هستههای پردازندههای گرافیکی در سرورهای هوش مصنوعی همیشه فعال بمانند، کیوکسیا یک حافظه انقلابی با نام XL-Flash SSD معرفی کرده است که ادعا میشود از سریعترین SSDهای بازار هم ۳ برابر سریعتر است. این درایو با استفاده از حافظه SLC و اتصال مستقیم به GPU، دادهها را با تأخیر بسیار پایین در اختیار مدلهای زبانی بزرگ (LLM) قرار میدهد.
یکی از بزرگترین گلوگاهها در سرورهای هوش مصنوعی، فرآیند انتقال داده بین حافظه ذخیرهسازی و پردازنده گرافیکی (GPU) است. در حال حاضر، این انتقال توسط پردازنده مرکزی مدیریت میشود که باعث افزایش چشمگیر تأخیر و زمان دسترسی به دادهها میشود. کیوکسیا (Kioxia) قصد دارد با فناوری جدید خود این مانع را برای همیشه از میان بردارد.
بر اساس گزارش Tom’s Hardware، شرکت کیوکسیا به تازگی از طرح یک حافظه SSD جدید رونمایی کرد که میتواند پارادایمهای فعلی ذخیرهسازی را به کلی دگرگون کند. این درایو که با نام «AI SSD» شناخته میشود، برای دستیابی به سرعت بیش از ۱۰ میلیون عملیات ورودی/خروجی در ثانیه (IOPS) در پردازش بلوکهای داده کوچک طراحی شده است؛ سرعتی که حداقل سه برابر بیشتر از سریعترین SSDهای پیشرفته امروزی است.

در همین رابطه بخوانید:
- بررسی اس اس دی datamag msi
- بررسی silicon power slim s55
راز دستیابی به سرعت ۱۰ میلیون IOPS: حافظه XL-Flash و کنترلر اختصاصی
برای رسیدن به این هدف بلندپروازانه، کیوکسیا در حال طراحی یک کنترلر کاملاً جدید است که به طور ویژه برای به حداکثر رساندن تعداد عملیاتهای ورودی و خروجی بهینهسازی شده است. این کنترلر به پردازندههای گرافیکی اجازه میدهد با سرعتی به دادهها دسترسی پیدا کنند که هستههای پردازشی آنها همواره ۱۰۰ درصد فعال باقی بمانند یا حداقل تأخیر دسترسی به SSD مانع اصلی برای دستیابی به این هدف نباشد.
قلب تپنده این SSD، حافظه SLC اختصاصی کیوکسیا با نام XL-Flash است. این حافظه با تأخیر خواندن بین ۳ تا ۵ میکروثانیه، بسیار سریعتر از حافظههای NAND سهبعدی متداول با تأخیر ۴۰ تا ۱۰۰ میکروثانیه عمل میکند. علاوه بر این، حافظههای SLC به دلیل ذخیره تنها یک بیت در هر سلول، دوام و سرعت دسترسی بالاتری دارند که برای بارهای کاری سنگین هوش مصنوعی حیاتی است. در حال حاضر، بهترین SSDهای دیتاسنتر در خواندن تصادفی بلوکهای 4K و 512B به سرعتی بین ۲ تا ۳ میلیون IOPS دست مییابند.
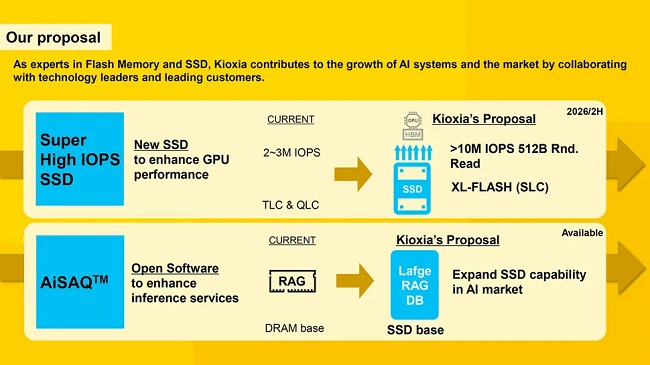
حذف پردازنده از معادله: ارتباط مستقیم SSD و GPU برای حداکثر کارایی
دیگر ویژگی انقلابی «AI SSD» کیوکسیا، بهینهسازی آن برای ارتباط مستقیم بین GPU و SSD است. این معماری با حذف CPU از مسیر انتقال داده، عملکرد را به شکل چشمگیری افزایش داده و تأخیر را به حداقل میرساند.
این SSD به طور خاص برای افزایش خواندن اطلاعات در بلوکهای ۵۱۲ بایتی بهینه شده است که آن هم دلیلی فنی دارد. مدلهای زبانی بزرگ (LLM)، برای واکشی پارامترها و اطلاعات، به دسترسیهای تصادفی و کوچک متکی هستند. از سوی دیگر، پردازندههای گرافیکی نیز با هدف مشغول نگه داشتن تمام هستههای خود، برای دسترسی به حافظه کش در بلوکهای ۳۲، ۶۴ یا ۱۲۸ بایتی بهینه شدهاند و خواندن بلوکهای ۵۱۲ بایتی با این معماری سازگاری بیشتری دارد.
در همین رابطه بخوانید:
- کنترلر جدید SM2324 با سرعت 4000 مگابایت بر ثانیه؛ آماده برای نسل بعدی SSDهای اکسترنال
- حافظه نسل بعدی در راه است؟ تمرکز اینتل بر ساخت رقیبی برای HBM
کیوکسیا این SSD را برای دو کاربرد اصلی در نظر گرفته است: سیستمهای آموزش هوش مصنوعی که در آنها مدلهای زبان بزرگ به دسترسی سریع و مکرر به دیتاستهای عظیم نیاز دارند و همچنین سیستمهای استنتاج (Inference) که از تکنیکهای RAG برای بهبود پاسخهای هوش مصنوعی استفاده میکنند.












نظر خود را اضافه کنید.
برای ارسال نظر وارد شوید
ارسال نظر بدون عضویت در سایت