
گزارش جدید متا از اجرای مدل هوش مصنوعی Llama 3 405B بر روی کلاستری با ۱۶,۳۸۴ پردازنده گرافیکی Nvidia H100 80GB حاوی اطلاعات جالبی درباره نرخ خرابی و مشکلات این محصول گرانقیمت انویدیا است.
متا اخیراً نتایج مطالعهای را منتشر کرده که جزئیاتی از اجرای مدل هوش مصنوعی Llama 3 405B بر روی کلاستری متشکل از ۱۶,۳۸۴ پردازنده گرافیکی Nvidia H100 80GB ارائه میکند. فرآیند آموزش مدل هوش مصنوعی متا ۵۴ روز طول کشیده و در این مدت، کلاستر مورد استفاده با ۴۱۹ مورد خرابی غیرمنتظره مواجه شد که به طور متوسط هر سه ساعت یک بار خرابی رخ داده بود. در نیمی از موارد خرابی، پردازندههای گرافیکی یا حافظه HBM3 بکار رفته در آنها مشکلساز شده بودند.
نرخ خرابی H100 80GB انویدیا در آموزش Llama 3 405B
یک جمله مشهور در دنیای ابرکامپیوترها وجود دارد که میگوید تنها قطعیت در سیستمهای بزرگ، خرابی است. ابرکامپیوترها دستگاههای بسیار پیچیدهای هستند که از دهها هزار پردازنده، صدها هزار تراشه دیگر و صدها کیلومتر کابل استفاده میکنند. در چنین ابرکامپیوتر پیشرفته و پیچیدهای، وقوع خرابی هر چند ساعت یک بار امری اجتنابناپذیر است، از همین رو این هنر توسعهدهندگان و طراحان آن است که سیستم را با وجود خرابیهایی که رخ میدهد، فعال نگه دارند.
طبق آنچه که گفته شد، به وضوح استفاده از ۱۶,۳۸۴ پردازنده گرافیکی برای تعلیم مدل هوش مصنوعی، آن را مستعد خرابی میکند. اگر این خرابیها به درستی مدیریت نشوند، خرابی تنها یک پردازنده گرافیکی میتواند کل فرایند آموزش را مختل کند و همه چیز به نقطه اول بازگردد. با این حال تیم Llama 3 توانسته از بیش از ۹۰ درصد زمان صرف شده برای آموزش این مدل هوش مصنوعی استفاده مفید کند.
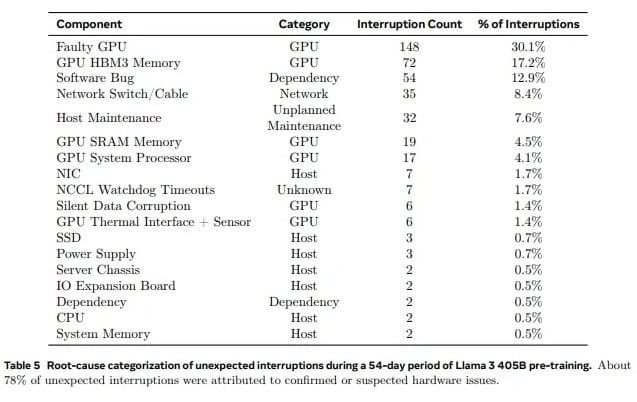
در یک دوره آزمایشی ۵۴ روزه، ۴۶۶ وقفه در کار رخ داد که ۴۷ مورد برنامهریزی شده و ۴۱۹ مورد غیرمنتظره بودند. وقفههای برنامهریزی شده به دلیل نگهداری خودکار بودند، در حالی که وقفههای غیرمنتظره عمدتاً از مشکلات سختافزاری ناشی میشدند. مشکلات مرتبط با پردازندههای گرافیکی بالاترین سهم را از وقفههای رخ داده داشتند و ۵۸.۷٪ از وقفههای غیرمنتظره را تشکیل میدادند. از ۴۱۹ واقعه رخ داده، تنها سه مورد نیاز به مداخله دستی جدی داشتند و بقیه به صورت اتوماسیون مدیریت شدهاند.
در همین رابطه بخوانید:
- Llama 3.1 معرفی شد؛ بزرگترین مدل هوش مصنوعی دنیا بهتر از GPT-4o!
از ۴۱۹ وقفه غیرمنتظره رخ داده، ۱۴۸ مورد (۳۰.۱٪) ناشی از خرابیهای مختلف پردازندههای گرافیکی (از جمله خرابیهای NVLink) بودند، در حالی که ۷۲ مورد (۱۷.۲٪) ناشی از خرابی حافظه HBM3 بودند. البته این خرابیها با توجه به مصرف حدود ۷۰۰ واتی پردازندههای گرافیکی Nvidia H100 و استرس بالای ناشی از گرمای تولید شده، چندان هم تعجبآور نیست. جالب اینجاست که تنها دو پردازنده مرکزی (CPU) در طول این ۵۴ روز خراب شدند!













نظر خود را اضافه کنید.
برای ارسال نظر وارد شوید
ارسال نظر بدون عضویت در سایت