
شرکت گوگل با رونمایی از خانواده مدلهای Gemma 4، مسیر تازهای را در توسعه هوش مصنوعی ترسیم کرده است؛ مسیری که تمرکز آن از مدلهای صرفاً ابری به سمت پردازش محلی، کاهش تأخیر و افزایش استقلال توسعهدهندگان تغییر یافته است. این خانواده بهعنوان مجموعهای از مدلهای متنباز طراحی شده تا امکان اجرای مستقیم روی طیف متنوعی از سختافزارها، از دیتاسنتر تا دستگاههای شخصی را فراهم کند.
تغییر رویکرد گوگل در معرفی این LLMها در حالی اتفاق میافتد که مدلهای سری Gemini همچنان عمدتاً در اکوسیستم ابری گوگل تعریف میشوند. در مقابل، Gemma 4 با هدف پاسخگویی به نیازهای جدیدی مانند پردازش آفلاین، حفظ حریم خصوصی و کاهش وابستگی به اینترنت توسعه یافته است.
معماری متنوع برای سناریوهای مختلف
خانواده Gemma 4 از چهار مدل با مقیاسهای متفاوت تشکیل شده که هرکدام برای سطح مشخصی از کاربردها بهینهسازی شدهاند. در رأس این مجموعه، مدلهای 26B و 31B قرار دارند که بهترتیب از معماری Mixture of Experts و Dense بهره میبرند.
در مدل 26B، تنها بخشی از پارامترها در زمان استنتاج فعال میشوند و همین موضوع باعث میشود تعادلی میان کارایی و مصرف منابع برقرار شود. در مقابل، مدل 31B با فعالسازی کامل پارامترها، تمرکز خود را بر ارائه حداکثر دقت و کیفیت خروجی گذاشته و بیشتر برای کاربردهای تخصصی و سناریوهای توسعه پیشرفته در نظر گرفته شده است.
این مدلها در حالت استاندارد قادرند در فرمت bfloat16 و بدون نیاز به کوانتیزهسازی روی سختافزارهایی مانند NVIDIA H100 اجرا شوند. با این حال، امکان کاهش دقت محاسباتی برای اجرا روی کارتهای گرافیک مصرفی نیز فراهم شده تا دسترسی به این مدلها محدود به زیرساختهای گرانقیمت نباشد.
در سطح پایینتر، مدلهای E2B و E4B قرار دارند که بهطور خاص برای دستگاههای کممصرف و سناریوهای Edge طراحی شدهاند. این مدلها با تمرکز بر کاهش مصرف حافظه و انرژی، قابلیت اجرا روی گوشیهای هوشمند، بردهایی مانند Raspberry Pi و حتی پلتفرمهای توسعهای نظیر Jetson Nano را دارند.
همکاری گوگل با Qualcomm و MediaTek در این بخش نشان میدهد که هدف، گسترش واقعی AI محلی در دستگاههای مصرفی است، نه صرفاً ارائه یک قابلیت آزمایشی.
تمرکز بر کارایی، استدلال و تعامل با ابزارها
از دید فنی، Gemma 4 بر پایه فناوری مدلهای پیشرفته Gemini 3 توسعه یافته و در حوزههایی مانند استدلال چندمرحلهای، تحلیلهای ریاضی و پیروی دقیق از دستورالعملها بهبود پیدا است. این پیشرفتها در عمل به معنای پاسخهای دقیقتر، توانایی حل مسائل پیچیدهتر و کاهش خطا در اجرای دستورات است.
در عین حال، گوگل این مدلها را همسو با روند روبهرشد «هوش مصنوعی عاملمحور» طراحی کرده است. به همین دلیل، قابلیتهایی مانند فراخوانی تابع بهصورت بومی، تولید خروجیهای ساختاریافته در قالب JSON و امکان تعامل مستقیم با APIها در آنها لحاظ شده است.
این ویژگیها باعث میشوند Gemma 4 تنها یک مدل زبانی نباشد، بلکه به ابزاری برای ساخت سیستمهای خودکار و جریانهای کاری پیچیده تبدیل شود.
کدنویسی در محیط آفلاین؛ رقابت با مدلهای ابری
یکی از کاربردهای کلیدی که گوگل در Gemma 4 روی آن تمرکز کرده، تولید و تحلیل کد است. در حالی که مدلهایی مانند Gemini Pro و Claude Code عمدتاً بهصورت سرویسهای ابری ارائه میشوند، هدف Gemma 4 ارائه کیفیتی مشابه در یک محیط کاملاً محلی است.
این موضوع بهویژه برای توسعهدهندگانی اهمیت دارد که با محدودیتهای امنیتی، هزینههای زیرساخت یا تأخیر شبکه مواجه هستند. البته دستیابی به چنین سطحی از عملکرد، همچنان وابسته به در اختیار داشتن سختافزار مناسب، بهویژه در مدلهای بزرگتر، خواهد بود.
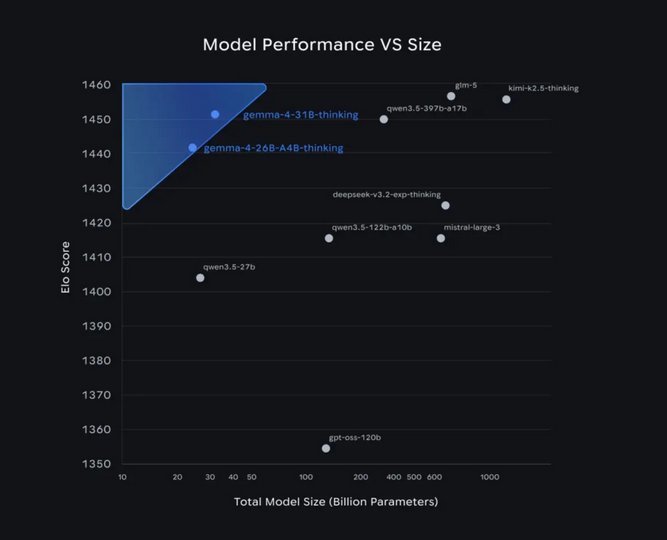
پشتیبانی گسترده و قابلیتهای چندرسانهای
از نظر قابلیتهای ورودی و پردازش، Gemma 4 نسبت به نسل قبل پیشرفت قابلتوجهی داشته است. این مدلها اکنون درک بهتری از دادههای بصری دارند و میتوانند وظایفی مانند استخراج متن از تصویر (OCR) یا تحلیل نمودارها را با دقت بالاتری انجام دهند.
همچنین مدلهای سبکتر به قابلیت تشخیص گفتار بومی مجهز شدهاند که در کاربردهای موبایلی اهمیت زیادی دارد.
پشتیبانی از بیش از ۱۴۰ زبان و افزایش ظرفیت پردازش متن تا ۲۵۶ هزار توکن در مدلهای بزرگ، نشان میدهد که این خانواده برای کاربردهای گسترده و چندزبانه طراحی شده است.
تغییر راهبردی در مجوز؛ سیگنال مثبت به توسعهدهندگان
یکی از مهمترین تغییرات در Gemma 4، کنار گذاشتن مجوزهای محدودکننده قبلی و حرکت به سمت Apache 2.0 است. این تغییر، بسیاری از نگرانیهای توسعهدهندگان درباره محدودیتهای حقوقی و امکان تغییر یکطرفه قوانین را برطرف میکند و مسیر استفاده تجاری و توسعه محصولات مبتنی بر این مدلها را هموارتر میسازد.
همکاری با انویدیا؛ از مدل تا اجرا روی دسکتاپ
همزمان با معرفی Gemma 4، شرکت انویدیا نیز از بهینهسازی کامل این مدلها برای پلتفرمهای سختافزاری خود خبر داده است؛ حرکتی که نشاندهنده همراستایی جدی میان توسعه مدل و زیرساخت اجرا است. بر این اساس، Gemma 4 نهتنها در دیتاسنترها، بلکه روی سیستمهای مبتنی بر RTX، ورکاستیشنها و حتی پلتفرمهایی مانند DGX Spark و ماژولهای Edge قابل اجرا خواهد بود.
نکته مهم این است که این پشتیبانی از همان روز نخست با اکوسیستم نرمافزاری همراه شده و ابزارهایی مانند Ollama و llama.cpp امکان استقرار سریع مدلها را فراهم میکنند. در عمل، این یعنی فاصله میان «معرفی مدل» و «استفاده واقعی» به حداقل رسیده است.
این همکاری همچنین نشان میدهد که صنعت در حال حرکت به سمت سناریویی است که در آن، مدلهای هوش مصنوعی نهتنها در ابر، بلکه بهصورت مستقیم روی سیستمهای شخصی اجرا میشوند. در چنین چارچوبی، مفهومی مانند «عامل هوشمند» دیگر یک سرویس دوردست نیست، بلکه میتواند روی دسکتاپ کاربر، در محیط توسعه یا حتی روی دستگاههای Edge اجرا شود.
جمعبندی؛ آغاز یک تغییر پارادایم در AI
Gemma 4 را باید بخشی از یک تغییر بزرگتر در صنعت هوش مصنوعی دانست؛ تغییری که در آن، تمرکز از مدلهای متمرکز ابری به سمت هوش مصنوعی توزیعشده و محلی در حال حرکت است. ترکیب مدلهای متنباز، بهینهسازی برای سختافزارهای متنوع و همکاری نزدیک با بازیگری مانند انویدیا، نشان میدهد که این مسیر نهتنها یک آزمایش، بلکه یک استراتژی بلندمدت است.
در این چشمانداز، رایانههای شخصی و دستگاههای مصرفی به پلتفرمهای واقعی اجرای AI تبدیل میشوند؛ جایی که کاربران و توسعهدهندگان میتوانند بدون وابستگی به ابر، مدلهای پیشرفته را مستقیماً در اختیار داشته باشند.













نظر خود را اضافه کنید.
برای ارسال نظر وارد شوید
ارسال نظر بدون عضویت در سایت