
چینیها این روزها با سرعت فزایندهای در حالی معرفی پیاپی مدلهای هوش مصنوعی با قابلیتهای اعجاب آور هستند. در همین رابطه استارتاپ چینی Moonshot AI از جدیدترین مدل خود با نام Kimi K2 Thinking رونمایی کرده که در آزمونهای استدلال، کدنویسی و حتی بنچمارکهای ریاضی از GPT-5 و Claude Sonnet 4.5 عملکرد بهتری دارد.
بر اساس دادههای رسمی Moonshot AI، این مدل در آزمون BrowseComp یا همان جستجوی ایجنتی وب به امتیاز 60.2 درصد رسیده که بالاتر از Deepseek-V3.2 و همچنین GPT-5 با امتیاز 54.9 درصد و Claude 4.5 با امتیاز 24.1 درصد است.

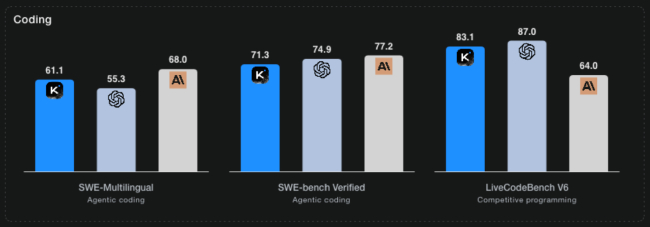
این مدل در آزمون HLE نیز با امتیاز 44.9 درصد رکورد تازهای ثبت کرده و در بنچمارک SWE-Bench Verified با امتیاز 71.3 درصد از مدلهای آمریکایی پیشی گرفته است. Kimi K2 Thinking حتی در بنچمارکهای ریاضی سطح بالا مانند AIME 2025 و HMMT 2025 نیز با GPT-5 برابری میکند.
بنچمارکهای هوش مصنوعی Kimi K2 Thinking
این موضوع برای نخستینبار نشان میدهد یک مدل متنباز میتواند در استدلالهای پیشرفته با مدلهای اختصاصی و پولی رقابت کند یا از آنها فراتر رود. مدل Kimi K2 Thinking بر پایه معماری Mixture of Experts (MoE) ساخته شده و در مجموع 1 تریلیون پارامتر دارد.
با این حال تنها 32 میلیارد پارامتر بهصورت همزمان فعال است تا کارایی و بهینگی سیستم حفظ شود. این مدل از 256 هزار توکن پشتیبانی میکند و بهکمک تکنیک Quantization توانسته مصرف حافظه و زمان تولید متن را تقریباً به نصف کاهش دهد.
مدل Kimi K2 Thinking هماکنون از طریق وبسایت رسمی kimi.com در دسترس قرار دارد. هزینه استفاده از API برابر با 0.60 دلار بهازای هر 1 میلیون توکن ورودی است. این رقم تقریباً نصف هزینه GPT-5 محسوب میشود.
Moonshot AI این مدل را تحت مجوز MIT اصلاحشده منتشر کرده است. طبق این مجوز، استفاده تجاری از مدل آزاد است، اما در صورتی که نرمافزار یا محصول مبتنی بر آن بیش از 100 میلیون کاربر فعال ماهانه داشته باشد یا بیش از 20 میلیون دلار درآمد ماهانه کسب کند، باید نام Kimi K2 بهطور واضح در رابط کاربری محصول درج شود.












نظر خود را اضافه کنید.
برای ارسال نظر وارد شوید
ارسال نظر بدون عضویت در سایت