
در زمینه هوش مصنوعی و یادگیری ماشین پردازندههای گرافیکی (GPU) بهدلیل تعداد زیاد هستهها از محبوبیت بیشتری نسبت به پردازنده مرکزی (CPU) برخوردار هستند. اما دانشمندان دانشگاه رایس الگوریتم جدیدی را بهکار گرفتهاند که کارآیی سی پی یو را در محاسبات هوش مصنوعی تا 15 برابر جی پی یو افزایش میدهد.
غالباً برای حل محاسبات پیچیده هوش مصنوعی از الگوریتمهای جستجوی غیرهوشمندانه نظیر Brute Force استفاده میشود. یعنی با استفاده از سختافزار قوی برای حل یک محاسبه پیچیده از روشهای جستجوی جامع استفاده میکنند.
بدون شک پردازشهای DNN (یادگیری عمیق ماشین) یکی از پیچیدهترین و سنگینترین عملیاتهای پردازشی است. به همین خاطر برنامهنویسانی که در این زمینه فعالیت دارند برای انجام پردازشهای خود از جی پی یو استفاده میکنند. زیرا پردازندههای گرافیکی بازدهی بهتری در این زمینه دارند.
اما Anshumali Shrivastava یکی از اساتید دانشگاه فنی مهندسی Rice Brown با کمک همکاران خود موفق شده الگوریتم جدیدی را طراحی کند که سرعت پردازندههای مرکزی نظیر AVX512 و AVX512_BF16 را در محاسبات DNN تا چندین برابر افزایش دهد.
وی در مصاحبهای با وبسایت TechXplore میگوید: «شرکتها میلیونها دلار پول را صرف بهینهسازی سیستمهای کامپیوتری خود را برای محاسبه پردازشهای هوش مصنوعی و DNN میکنند. در واقع میتوان گفت که تمام بخشهای این صنعت به بهبود بازدهی محاسبات ماتریسی وابسته هستند»
ایشان میافزاید: «همه بهدنبال سختافزارهای اختصاصی و با یک معماری خاص برای به حداکثر رساندن بازدهی در محاسبات ماتریسی هستند. اما من میگویم بیایید نگاهی دوباره به الگوریتمها داشته باشیم و آنها را بهینه کنیم.»
Shrivastava برای اثبات ادعای خود از SLIDE که یک موتور برپایه Open-MP و مبتنی بر زبان برنامهنویسی ++C استفاده نمود. موتور SLIDE که به صورت تصادفی هش هوشمند را با موازی سازی چند هستهای در سی پی یو ترکیب می کند.
این موتور پردازشی بهشکل ویژهای برای پردازندههای AVX512 و AVX512-BF16 شرکت Intel بهینه شده است. نتایج بررسیهای انجام شده توسط محققان دانشگاه Rice منتشر شده است:
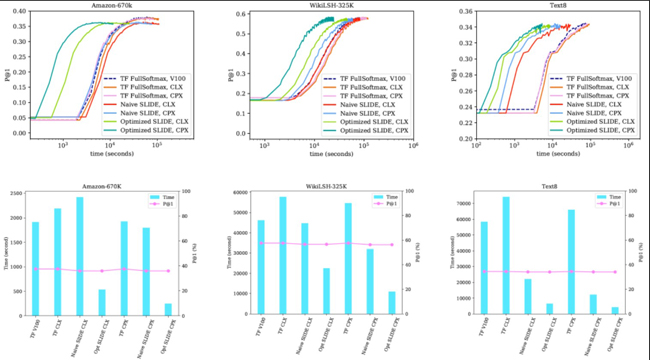
این موتور در هر بروزرسانی برای شناسایی Neuronها از LSH یا همان (Locality Sensitive Hashing) استفاده میکند که سبب بهینه سازی عملکرد پردازندهها شده و آنها را قادر میسازد بیش 200 میلیون پارامتر Neural Network را یاد بگیرند.
از لحاظ میزان زمان صرف شده، این موتور میتواند بسیار سریعتر و بهینهتر از پیاده سازی TensorFlow در کارت گرافیکهای سری Nvidia V100 عمل کند.
شبنم دقاقی، یکی دیگر از اساتید دانشگاه Rice، میگوید: «بازدهی مبتنی بر جدول هش در حال حاضر در پردازندههای گرافیکی بهتر است. اما پردازندههای مرکزی نیز در حال پیشرفت در این زمینه هستند.»
محققان برای سرعت بخشیدن به عملیات هش کردن (Hashing)، الگوریتمها را برداری و کوانتیده کردهاند تا در پردازندههای AVX512 و AVX512-BF16 شرکت Intel عملکرد بهینهتری ارائه کنند. آنها همچنین برخی بهینهسازیها را نیز در زمینه حافظه پیاده کردهاند.
با استفاده از الگوریتم جدید میتوان گفت که پردازندههای سری Cooper Lake اینتل میتوانند کارت گرافیک Nvidia Tesla V100 را پشت سر گذاشته و تا 7.8 برابر در Amazon-670K و 5.2 برابر در WikiLSHTC-325K و 15.5 برابر در Text8 بازدهی بالاتری داشته باشند.
در واقع حتی یک پردازنده سری Cascade Lake نیز با بهینهسازی میتواند 2.55 تا 11.6 برابر عملکرد بهتری نسبت به کارت گرافیک Nvidia Tesla V100 داشته باشد. در ادامه به جدول مقایسه زمانی که توسط دانشگاه Rice منتشر شده توجه کنید.
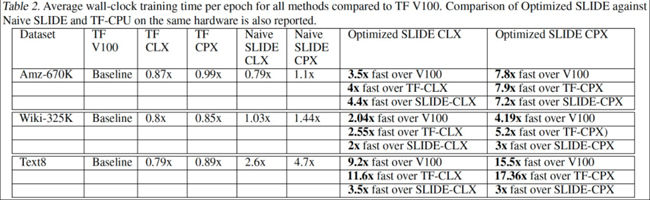
بدون شک بهینه سازی الگوریتمهای DNN برای پردازندههایی که از AVX512 و AVX512-BF16 پشتیبانی میکنند کاملاً منطقی بهنظر میرسد. چرا که این پردازندهها امروزه در اغلب دیتاسنترها و سرورها مورد استفاده قرار میگیرند و چه بهتر که از تمام قابلیتهای آنها و حداکثر توان پردازشی آنها بهره ببریم.
نکته دیگری که بایستی به آن توجه نمود اینست که پردازندههای مذکور به راحتی کارتهای گرافیک قابل تهیه نیستند. در آخر این سوال مطرح میشود که آیا پردازنده گرافیکی Nvidia A100 میتواند پردازندههای سری Cascade Lake شرکت Intel را شکست دهد؟












نظر خود را اضافه کنید.
برای ارسال نظر وارد شوید
ارسال نظر بدون عضویت در سایت