








همانطور که اطلاع دارید چند ماهی میشود که کارتهای گرافیک سری GTX 1000 کمپانی انویدیا با معماری بسیار مدرن و کارآمد Pascal روانه بازار شدهاند. در این مقاله قصد داریم به صورت مفصل به کالبدشکافی این معماری بپردازیم و قابلیتها و ویژگیهای جدیدی که کارتهای گرافیک مبتنی بر این پلتفرم با خود به همراه دارند را به صورت کامل تشریح کنیم. اکیداً توصیه میکنیم مطالعه این مقاله ارزشمند را از دست ندهید.
مقدمه و تشریح معماری
اگر بخواهیم با یک دید کلی در مورد معماری جدید Pascal انویدیا اظهار نظر کنیم میتوان اینگونه بیان کرد که معماری پاسکال (معماری پیاده سازی شده در تراشه GP104) به نوعی ترکیبی از تکنولوژیهای قبلی و جدید انویدیا محسوب میشود. معماری Maxwell و محصولات مبتنی بر آن بدون شک یکی از موفقترین پروژههای این کمپانی چه در سطح مصرف کنندگان عادی و چه در سطح حرفهای و محصولات Workstation محسوب میشدند و همین امر باعث شده تا انویدیا در محصولات مصرف کنندههای عادی (برای مثال Gamer ها و کاربران عادی) مبتنی بر معماری Pascal را نیز با کمترین تغییرات، نسبت به معماری Maxwell روانه بازار کند. در معماری پاسکال تمامی زیرساختهای پایه نظیر واحدهای محاسبه و منطق (ALUs)، واحدهای ساخت بافتها (Texture units)، واحدهای تصویرسازی (ROPs) و حافظههای Cache همگی تقریباً شبیه همانهایی هستند که قبلاً در GM2xx پیاده سازی شده بودند.
در واقع انویدیا در GPU های سطح به اصطلاح Consumer یا مصرف کنندگان عادی با معماری Pascal سعی کرده تا با افزایش سرعت Clock هسته و تعداد Shader Processor ها قدرت پردازش اطلاعات را در GP104 به مرز 8.9TFLOPs برساند و در نهایت به استفاده از حافظههای پرسرعت و جدید GDDR5X و البته بهروزرسانی رابط حافظه این پردازنده گرافیکی بسیار قدرتمند را بهخوبی تغذیه کند.
(Nvidia GP104 (Pascal Architecture

در تصویر بالا بلاک دیاگرام تراشه گرافیکی (GPU) به کار رفته در کارت گرافیکی GTX 1080 را ملاحظه میکنید. این تراشه (GP104) پس از GP102 (تراشه گرافیکی به کار رفته در NVIDIA Titan X Pascal) قدرتمندترین پردازنده گرافیکی (در سطح مصرف کنندگان عادی) مبتنی بر معماری Pascal محسوب میشود. در این تراشه 2560 CUDA Core در قالب 20 واحد SM در فرکانس بیش از 1733MHz فعالیت میکنند. GP104 به صورت کلی و همانند GM204 (تراشه گرافیکی به کار رفته در GTX 980) از 4 واحد بسیار بزرگ GPC) Graphics Processing Cluster) تشکیل شده که هر یک از این واحدها 5 واحد SM یا همان Streaming Multiprocessors را درون خود جای دادهاند. این در حالی است که هر یک از واحدهای GPC تراشه GM204 دارای 4 واحد SM بودند. در تصویر زیر میتوانید بلاک دیاگرام تراشه GM204 را نیز ملاحظه کنید:
(NVIDIA GM204 (MaxwellArchitecture
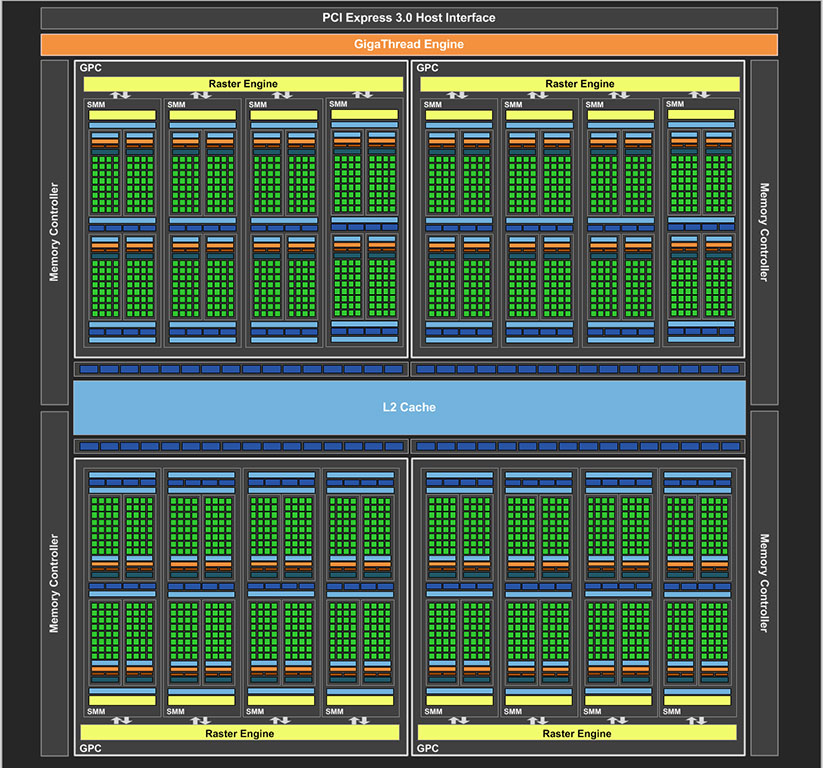
در واقع به صورت کلی تفاوت ساختاری میان تراشه گرافیکی GP104 (تراشه به کار رفته در GTX 1080) و GM204 (تراشه به کار رفته در GTX 980) در همین 1 عدد واحد SM بیشتر در GPC ها خلاصه میشود؛ اما اجازه دهید برای یادآوری هم که شده کمی بیشتر وارد جزئیات ساختاری واحدهای GPC و SM شویم.
NVIDIA GP104 - GPC
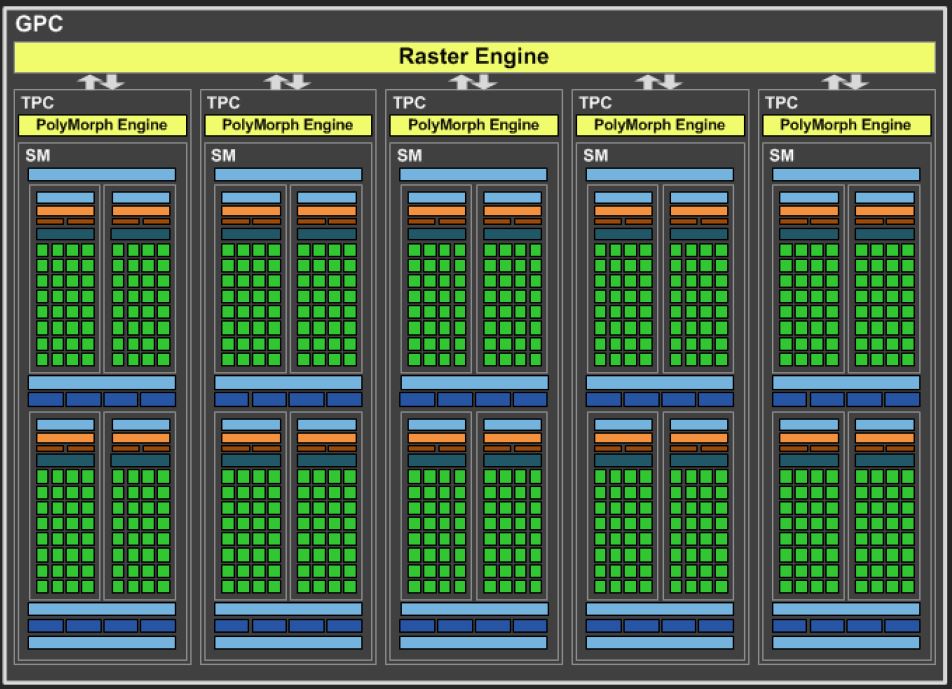
خب همانطور که اشاره شد هر واحد GPC در معماری پاسکال 5 واحد SM را درون خود جای داده است که هر یک از واحدهای SM دارای 128 عدد CUDA core (واحدهای کوچک مربع شکل سبز رنگ) و 8 عدد Texture Unit (واحدهای مستطیل شکل به رنگ آبی تیره) هستند. حال برای محاسبه CUDA Core های کل این تراشه کافی است 128 را در تعداد SM های هر واحد GPC ا(عدد 5) ضرب کنید و نتیجه به دست آمده را مجدداً در تعداد واحدهای GPC این تراشه (عدد 4) ضرب کنید. نتیجه به دست آمده عدد 2560 عدد CUDA Core خواهد بود. حال اگر همین روال را برای واحدهای Texture Unit نیز تکرار کنید به عدد 160 خواهید رسید. پس 1 واحد SM بیشتر در هر GPC باعث افزایش 512 عددی CUDA core ها و همینطور افزایش 32 عدد واحدهای Texture Unit تراشه GP104 نسبت به GM204 شده است. از سوی دیگر بر خلاف GM204 که دارای 4 کنترلر حافظه 64bits (جمعاً 256bits) و 16 ROP Units به ازای هر کنترلر حافظه (جمعاً 64 عدد) بود، در GP104 هشت کنترلر حافظه 32bits تعبیه شده (جمعاً 256bits) که هر یک از این کنترلرها توسط 8 عدد ROP Units تغذیه میشوند. کاملاً مشخص است که رابط حافظه و تعداد واحدهای ROP تغییر نکرده است ولی انویدیا با در نظر گرفتن حافظههای بسیار پرسرعت GDDR5X با فرکانس مؤثر 10000MHz برای این تراشه قدرتمند، پهنای باند تئوری بیش از 320GB/sec را برای آن فراهم کرده است.
NVIDIA GP104 –SM Unit

در تصویر بالا نیز جزئیات هر واحد SM را ملاحظه میکنید. واحدهای SM معماری پاسکال دقیقاً مشابه معماری مکسول طراحی شدهاند.
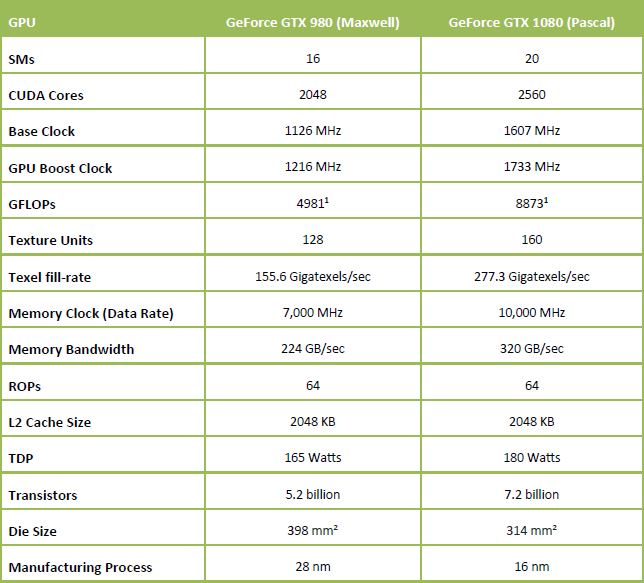
اما بهعنوان جمع بندی نهایی همانطور که در جدول بالا ملاحظه میکنید روی هم رفته 4 عدد واحد SM بیشتر و به ازای آن 512 عدد CUDA Core و 32 عدد Texture Unit بیشتر به همراه بیش از 517MHz سرعت کلاک بیشتر GPU و 3000MHz سرعت کلاک بیشتر حافظه که در عمل باعث افزایش 43% پهنای باند حافظه و توان عملیاتی واحدهای ROP میشود، روی کاغذ باعث افزایش 78% کارایی خام GTX 1080 در برابر GTX 980 میشوند. البته این در حالی است که با وجود افزایش 38% تعداد ترانزیستورها و البته به لطف تکنولوژی ساخت TSMC's 16 nm FinFET اندازه Die در تراشه GP104 حدوداً بیش از 21% کوچکتر شده و توان مصرفی این مجموعه نیز تنها 9% افزایش یافت است.
معماری پاسکال: طراحی شده برای سرعت
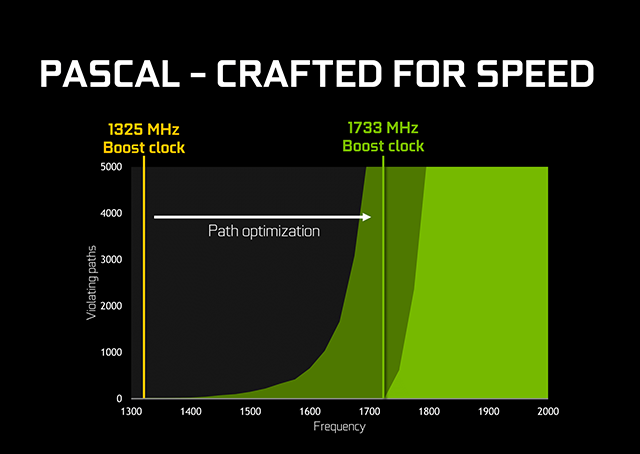
همانطور که اشاره شد یکی از مهمترین عواملی که باعث افزایش کارایی در معماری پاسکال شده است افزایش بیش از 45% سرعت کلاک GPU نسبت به معماری مکسول است. این میزان افزایش سرعت کلاک در عمل باعث بالا رفتن توان مصرفی تراشه خواهد شد ولی به لطف تکنولوژی 16nm FinFET به کار رفته در ساخت میلیونها ترانزیستور به کار رفته در این تراشه و البته از آن مهمتر بهینه سازیهای فراوان پیاده سازی شده در تایمینگ بخشهای مختلف این تراشه مدرن، تراشههای گرافیکی مبتنی بر معماری Pascal یکی از پربازدهترین GPU های حال حاضر محسوب میشوند.
GPU Boost 3.0
چند سالی میشود که تراشههای گرافیکی ساخت کمپانی انویدیا این قابلیت را دارند که علاوه بر فرکانس پایه هسته GPU، با توجه به دمای هسته و البته میزان Load آن، در فرکانسهای بالاتر از این مقدار نیز فعالیت کنند. در واقع این مکانیسم که تحت عنوان GPU Boost معرفی شده است یک فرآیند خودکار اورکلاک محسوب میشود و تأثیر بسزایی نیز در افزایش کارایی تراشههای گرافیکی دارد. انویدیا در معماری Pascal از نسخه سوم این مکانیسم رونمایی کرده است. در ادامه قابلیتهای جدید این نسخه را بررسی میکنیم.
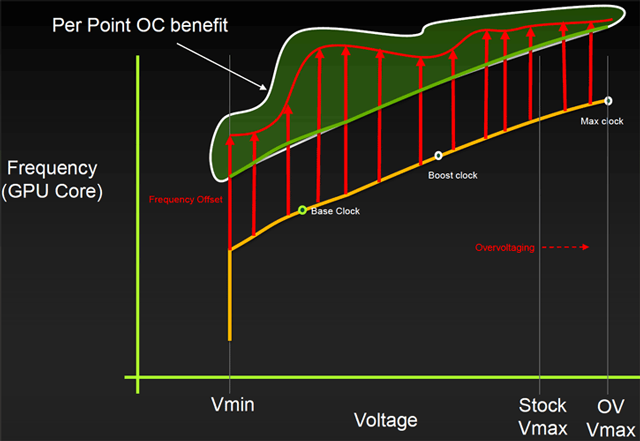
یکی از اساسیترین تغییرات در GPU Boost 3.0 تحت عنوان per voltage point frequency offsets معرفی شده است. در این تکنیک بر خلاف نسل قبل که با فعال شدن حالت GPU Boost، ولتاژ هسته GPU نیز یک باره و یا حداکثر در چند بازه محدود افزایش مییافت در نسخه جدید برای هر مقدار افزایش فرکانس نسبت به فرکانس پیش فرض، ولتاژ مخصوص تعیین شده است. این امر باعث کاهش تلفات انرژی و کنترل بیش از پیش حرارت متصاعد شده از GPU میشود. در نتیجه این امکان فراهم میشود که فرکانس Boost نسبت به مدلهای مشابه نسل قبل به صورت محسوسی افزایش یابد؛ اما این امر شاید تا حدودی اورکلاک کارتهای گرافیک مبتنی بر این معماری را پیچیدهتر کند. برای مثال در این معماری برای اعمال ولتاژ بیشتر به GPU دیگر گزینهای برای تغییر مقادیر مختلف ولتاژ با واحد ولت مشاهده نمیشود و این امکان فراهم شده است که میزان انحراف ولتاژ از محدوده ولتاژ پیش فرض را تنها با تعیین درصد انحراف تعیین کرد. همچنین در این معماری گزینهای برای غیرفعال کردن محدودیتهای مرتبط با میزان Load بر روی GPU نیز در نظر گرفته شده است. پس در واقع یکی از مهمترین پارامترهایی که در این معماری دست یابی به فرکانسهای بالاتر را تسهیل میکند بدون شک دمای GPU خواهد بود.
GDDR5X Memory
پشتیبانی تراشههای گرافیکی مبتنی بر معماری پاسکال از حافظههای GDDR5X با فرکانس بیش از 10GHz بدین معناست که این تراشهها و کنترلر حافظه تعبیه شده در آنها قابلیت تشخیص بیتهای 0 و 1 را در فاصله زمانی کمتر از 100 picoseconds (ps) را دارا میباشند. این بدان معنا است که برای حفظ پارامترهای Signaling در این فرکانس بسیار بالا، طراحی کنترلر حافظه، مدارهای مرتبط با بخش ورودی و خروجی و از آن مهمتر طراحی PCB برای داشتن ارتباطی پایدار و بدون افت کارایی باید دچار تغییرات فراوانی شده باشند.

در واقع در طراحی کانال ارتباطی میان Die تراشه گرافیکی و چیپ ها حافظه باید به کوچکترین جزئیات نیز توجه شود. در اینگونه ارتباطات، سرعت عملیاتی و واقعی رابط حافظه تنها توسط ضعیفترین سیگنال گذرگاه تعیین میشود. در طراحی جدید هر سیگنال در امتداد مسیر بسته خود از GPU تا چیپ های حافظه به صورت دقیق بررسی و مورد مطالعه قرار گرفته تا هر گونه افت دامنه سیگنال، تداخل و ناپیوستگیهای موجود شناسایی شده و تمهیدات لازم برای به حداقل رساندن آنها به کار گرفته شود.
به گفته انویدیا تمامی تمهیداتی که در کانالهای ارتباطی و مدارهای ورودی و خروجی این معماری اجرا شده تنها برای پایداری ارتباط با فرکانس تا 10GHz عملیاتی نشدهاند. بلکه این طراحی بهگونهای است که حتی محصولات آینده و با پهنای باند بهمراتب بالاتر از این را نیز در بر میگیرد. در واقع همین حالا نیز برخی از تولید کنندگان چیپ های حافظه از برنامه برای تولید حافظههای GDDR5X با سرعت بیش از 16Gbps خبر میدهند. حافظههایی که در مقایسه با پرسرعتترین چیپ های GDDR5 حال حاضر بیش از 2 برابر سریعتر خواهند بود!
در تصویر بالا سیگنال ارتباطی حافظههای GDDR5X را در فرکانس 10GHz و سایر بهینه سازیهای پیاده سازی شده در مدارهای ورودی و خروجی و کانالهای ارتباطی را ملاحظه میکنید.
Enhanced Memory Compression
همانند معماری Maxwell تراشهای جدید مبتنی بر معماری Pascal نیز از تکنیک فشرده سازی بدون افت کیفیت (lossless memory compression) اطلاعات حافظه، جهت کاهش وابستگی به پهنای باند بالای ارتباط، پشتیبانی میکنند. کاهش نیاز به پهنای بالا فراهم شده توسط فشرده سازی اطلاعات حافظه به صورت کلی این مزیتها را در پی دارد:
- کاهش حجم اطلاعات نوشته شده در حافظه
- کاهش حجم اطلاعات منتقل شده از حافظه به L2 Cache
- کاهش حجم اطلاعات رد و بدل شده بین واحدهای مختلف GPU مانند Texture Unit و حافظه frame buffer
Pipeline های فشرده سازی GPU در این معماری از چندین الگوریتم مختلف فشرده سازی پشتیبانی میکنند و البته در شرایط مختلف به صورت هوشمند و در کمترین زمان ممکن بهترین الگوریتم را برای فشرده سازی اطلاعات انتخاب میکنند. یکی از این مهمترین و مدرنترین این تکنیکهای فشرده سازی الگوریتم Delta Color Compression است.

در این الگوریتم GPU تفاوتهای میان پیکسلها را در یک بلوک محاسبه میکند و این بلوک را بهعنوان مجموعهای از پیکسلهای مرجع بهعلاوه ارزش دلتا نسبت به مقدار مرجع ذخیره میکند. اگر دلتاها کوچک باشند پس تعداد بیتهای کمتری به ازای هر پیکسل برای ذخیره شدن در حافظه نیاز خواهد بود. اگر نتیجه (مقدار حافظه اشغال شده) جمع بندی شده دادههای مرجع بهعلاوه ارزش عدد دلتا، نصف حالت فشرده سازی نشده باشد، در این حالت تکنیک فشرده سازی اطلاعات با استفاده از الگوریتم Delta Color Compression موفق بوده است و در نهایت اطلاعات با نصف حجم اصلی خود ذخیره شدهاند (2:1 compression)
در تراشه گرافیکی GP104 قابلیتها و توان عملیاتی الگوریتم فشرده سازی Delta Color Compression به میزان قابل توجهی بهینه سازی شده است:
- بازدهی و توان عملیاتی فشرده سازی حالت 2:1 در مقایسه با نسل قبل به میزان قابل توجهی افزایش داشته است
- اضافه شدن حالت فشرده سازی 4:1 برای پوشش مواردی که به ازای هر پیکسل بهعلاوه دلتا مورد نظر بسیار کوچک هستند و این قابلیت را دارند تا در ¼ فضای حالت فشرده سازی نشده خود ذخیره شوند.
- اضافه شدن حالت فشرده سازی 8:1 که به زبان ساده به نوعی ترکیب حالت 4:1 و 2:1 محسوب میشود

فشرده سازی رنگ در معماری Pascal، فشرده سازی رنگ در معماری Maxwell، تصویر اصلی بدون فشرده سازی
در تصویر بالا صحنهای از بازی معروف Project CARS را ملاحظه میکنید که به روشنی عملکرد تکنیک فشرده سازی رنگ را در معماری Pascal در مقایسه با معماری Maxwell نشان میدهد.
در این تصویر نقاطی که فشرده سازی رنگ در آن با موفقیت عملیاتی شده به رنگ ارغوانی ملاحظه میکنید. کاملاً مشخص است که معماری مکسول تقریباً قسمت اعظمی از رنگهای تصویر را فشرده سازی کرده ولی از پس فشرده سازی پوشش گیاهی و بخشهایی از اتومبیل بر نیامده است؛ اما در معماری پاسکال تنها بخشی از سمت چپ تصویر فشرده سازی نشده است.
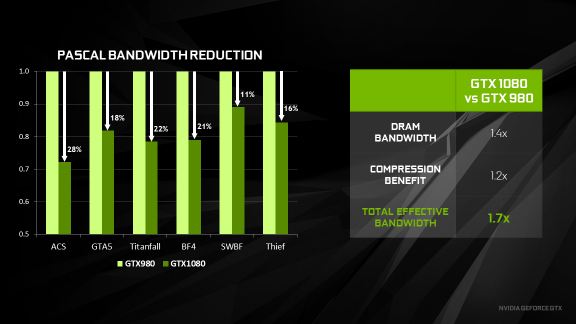
روی هم رفته و در تستهای عملی صورت گرفته عملکرد فشرده سازی رنگ در معماری پاسکال باعث افزایش 20 درصدی بازدهی پهنای باند حافظه نسبت به معماری Maxwell میشود. حال اگر این میزان را با افزایش بیش از 40 درصدی پهنای باند حافظه به لطف چیپ های پرسرعت GDDR5X 10GHz جمع کنیم به این نتیجه خواهید رسیم که پهنای باند عملیاتی در معماری Pascal بیش از 1.7 برابر نسبت به معماری Maxwell بیشتر شده است.
محاسبات ناهمزمان (Asynchronous Compute)
بار پردازش بازیهای رایانهای مدرن به صورت فزایندهای در حال پیچیده شدن است. یکی از مهمترین عوامل این امر پردازش چند کار مستقل و البته ناهمزمان است که به صورت تنگاتنگ با یکدیگر تعامل دارند تا در نهایت به کمک هم تصویر نهایی را رندر کنند.
چند مثال درباره بار پردازش غیر همزمان:
- پردازش فیزیک و صدا مبتنی بر GPU
- تصاویر رندر شده همراه با Postprocessing
- پردازش ناهمزمان پیچ و تاب و زمان: نوعی تکنیک استفاده شده در واقعیت مجازی که تصویر نهایی را با توجه به وضعیت سر دقیقاً قبل از نمایش نهایی تصویر بازسازی میکند
این نوع پردازشهای غیر همزمان دو سناریو جدید برای طراحان GPU به وجود میآورد که باید در نظر گرفته شوند.
سناریو اول شامل بار پردازشهایی است که با یکدیگر تداخل دارند. انواع خاصی از بارهای پردازش که به صورت کامل تمام منابع GPU را اشغال نمیکنند. در این مواقع GPU باید به صورت هوشمند منابع خود را بین هر دو بار پردازش به اشتراک بگذارد و این کار بهگونهای مدیریت کند تا بازدهی پردازش اطلاعات نیز قابل قبول باشد. پردازش گرافیکی تصویر در کنار پردازش فیزیک دبه صورت همزمان یک مثال خوب برای این سناریو محسوب میشود.
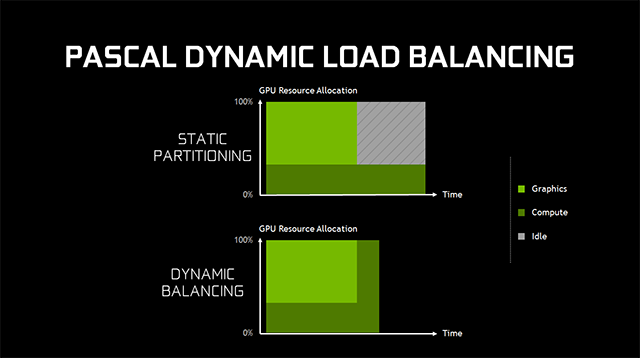
برای بارهای پردازش که با یکدیگر تداخل دارند معماری پاسکال پشتیبانی از تکنیک dynamic load balancing را در چنته دارد. در تراشههای گرافیکی مبتنی بر معماری Maxwell این نوع از پردازشها توسط پارتیشن بندی استاتیک (static partitioning) زیرمجموعههایی از GPU که پردازش گرافیکی و پردازش همه منظوره را انجام میدهند صورت میگیرند. این تکنیک به شرطی کارآمد است که تعادل کار بین دو بار پردازش، تقریباً منطبق با نسبت پارتیشن بندی مورد نظر باشد. با این حال اگر بار پردازش همه منظوره بیش از پردازش گرافیکی طول بکشد و هر دو برای پایان نهایی این پردازش نیاز به تکمیل شدن بار پردازش خود داشته باشند. بخشی از GPU که برای پردازش گرافیکی پارتیشن بندی شده بود عملاً بلااستفاده میماند.
در تکنولوژی سخت افزاری dynamic load balancing پیاده سازی شده در معماری Pascal این امکان وجود دارد که هر دو بار پردازش نام برده در صورت وجود منابع خالی در GPU به صورت پویا از منابع نام برده برای افزایش کارایی و بازدهی عملیاتی استفاده کنند.
Simultaneous Multi-Projection Engine
موتور پردازش همزمان چند تصویره یا همان Simultaneous Multi-Projection Engine یک واحد سخت افزاری جدید است که در بخش PolyMorph Engine در انتهای geometry pipeline و درست در مقابل واحد تصویرسازی (Raster Unit) قرار دارد. همانطور که از اسم آن پیداست، وظیفه واحد (Simultaneous Multi-Projection (SMP ایجاد بینش های متفاوت از یک جریان شکل هندسی است که همین امر SMP را تبدیل به یکی از مراحل سایه زنی بالادستی کرده است.

این بخش قادر است تا حداکثر 16 طرح و بینش مختلف از پیش تنظیم شده یک شکل هندسی را پردازش کند. در تمام حالات ممکن خلق تصاویر، پردازش اطلاعات توسط شتاب دهندههای سخت افزاری انجام میشود و جریان پردازش اطلاعات هیچ گاه پردازنده گرافیکی را ترک نمیکند. از آنجا که پردازش توسعه چند تصویره پس از واحدهای مربوط به ترسیم هندسی تصویر اتفاق میافتد، برنامههای سازگار با این تکنیک، تمامی عملیاتی که باید در واحدهای سایه زدن بالادستی انجام میشدند را بهمراتب کاهش میدهند. این عملیات حذف شده بهویژه در زمانی که GPU با تکنیکهای تصویرسازی هندسی پیچیده مثل Tessellation روبرو میشود پراهمیت هستند. در برخی موارد خاص، موتور SMP میتواند عملیات مربوط به پردازش هندسی تصاویر را تا حداکثر 32 برابر کاهش دهد.
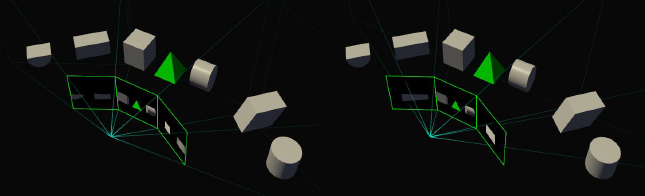
همانطور که در تصویر بالا ملاحظه میکنید یکی از نمونههای کاربردی SMP اصلاح میدان دید مطلوب در صفحه نمایشهای 3 گانه به صورت فراگیر است.
همچنین همانطور که مطلع هستید به لطف تکنولوژیهای جدید صفحه نمایشهای LED و OLED شاهد عرضه صفحه نمایشهای خمیده (Curved) و عینکهای واقعیت مجازی (VR) مجهز به عدسیها و صفحه نمایشهای مختلف هستیم که هر یکی از این تکنولوژیهای نمایش تصویر نیاز به تصویرسازی مختص به خود هستند. در تصویر زیر انواع مختلف تکنولوژیهای نمایش تصویر موجود در حال حاضر و یا در حال توسعه آینده نزدیک را ملاحظه میکنید.

پردازندههای گرافیکی کنونی از تمامی این صفحه نمایشها پشتیبانی میکنند ولی به صورت کاملاً ناکارآمد و یا با مراحل متعدد پردازش تصویر و پیچ و تاب دادنهای مختلف برای مطابقت با خروجی نهایی مورد نیاز. GPU های با معماری Maxwell دارای برخی قابلیتهای ابتدایی Multi-Resolution بودند که در واقع پیش نمایشی از مدل عملیاتی واحد SMP در معماری Pascal محسوب میشد. پردازندههای گرافیکی مبتنی بر معماری مکسول میتوانستند دقیقاً 90 درجه تصویر را بچرخانند (بهعنوان مثال برای نگاشت مکعب) و یا با گرفتن یک جهت تصویر واحد مقیاس آن را با رزولوشن بخشهای مختلف نمایشگر تطبیق دهند. این تکنیکها علیرغم مثمر ثمر بودن برای برخی کاربردها نظیر VXGI، ولی در بسیاری از حالتهای مختلف نمایشگرهای جدید ناکارآمد هستند و بازدهی کارایی مناسبی ندارند.
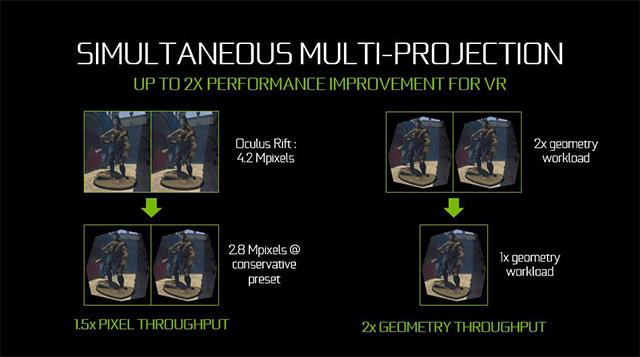
به لطف موتور Simultaneous Multi-Projection Engine و قابلیتهای آن در اداره نمایش چندین تصویر با پیچ و تاب و چرخش مختلف در آن واحد، پردازندههای گرافیکی مبتنی بر معماری Pascal این قابلیت را دارند تا به صورت کاملاً کارآمد و با بازدهی کارایی بالا در سریعترین زمان ممکن بهترین خروجی را برای نمایشگرهای نام برده فراهم کنند. این موتور پردازش هندسی مدرن با پشتیانی از تکنیکهایی نظیر Projections in 3D Graphics، Perspective Surround، Single Pass Stereo و Lens Matched Shading قادر است تا در حالتهای مدرن نمایش تصاویر در عینکهای واقعیت مجازی (VR) بهترین کیفیت ممکن در کنار کارایی بسیار بهتر از پردازندههای گرافیکی نسلهای قبل ارائه دهد.
رابط جدید و بهبود یافته SLI
گیمرهای حرفهای برای دستیابی به کارایی فوقالعاده بالا در وضعیتهایی که از چند نمایشگر با رزولوشنهای بالای 4K و 5K استفاده میکنند به پیکربندیهای 2 یا چندگانه Multi GPU تحت عنوان SLI تکیه میکنند. یکی از مهمترین اجزاء در پیکربندی SLI نیز پل SLI یا همان SLI Bridge است که در واقع یک رابط دیجیتال برای جابجایی اطلاعات تصویر بین کارتهای گرافیک Geforce در این سیستم محسوب میشود.
کارتهای گرافیکی رده بالای Nvidia Geforce که از پیکربندیهای 3 و 4 گانه SLI پشتیبانی میکنند دارای 2 عدد از این رابطها بر روی PCB خود هستند. علت وجود رابط دوم در این حالتها ارتباط میان سایر کارتهای گرافیک با کارت گرافیک اصلی (کارت گرافیکی که ورودی یا ورودیهای تصاویر مانیتورها به آن متصل شده است) جهت هماهنگی و ارسال اطلاعات مرتبط با رندر فریمها است و تا قبل از معماری Pascal هر یکی از این رابطها به صورت مستقل عمل میکردند.

اما در معماری Pascal این دو رابط به یکدیگر لینک شدهاند تا پهنای باند ارتباط میان دو کارت گرافیک افزایش یابد. این حالت جدید dual-link SLI این قابلیت را فراهم میکند که هر دو رابط SLI در کنار هم نمایشگرهای با رزولوشنهای بالا و یا پیکربندیهای فراگیر مجهز به 3 نمایشگر را با سرعت بهمراتب بیشتر نسبت به نسلهای قبل تغذیه کنند.

Dual-link SLI تنها توسط پلهای جدید تحت عنوان SLI HB پشتیبانی میشود. این پلهای جدید ارتباط سریع میان دو کارت گرافیک را تسهیل میکنند، هر دو رابط SLI را در این ارتباط شرکت میدهند و موجب فعال شدن وضعیت ارتباط با سرعت کلاک 650MHz میان دو کارت گرافیک GTX 1080 میشود (این نکته را مد نظر داشته باشید که پیکربندی SLI توسط پلهای قدیمی نیز امکان پذیر است ولی در این حالت حداکثر سرعت کلاک ارتباط 400MHz خواهد بود و حداکثر کارایی این پیکربندی آشکار نخواهد شد).

البته لازم به ذکر است پلهای SLI مجهز به LED در پیکربندی دوگانه GTX 1080 از فرکانس 650MHz و پهنای باند بالای این ارتباط پشتیبانی میکنند.
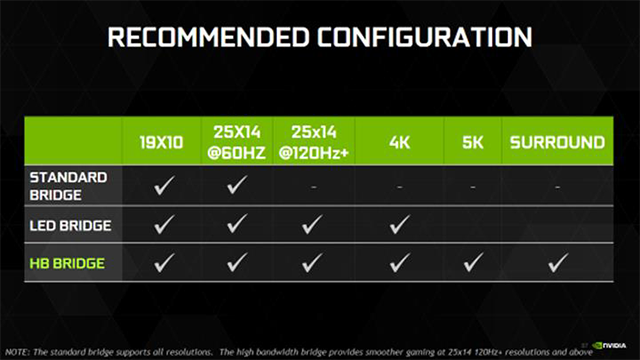
پس مدنظر داشته باشید که برای ارتباط پرسرعت و پشتیبانی از نمایشگرهای 4K و 5K و همینطور ترکیب فراگیر چند نمایشگر به صورت همزمان باید از پلهای جدید مجهز به LED و یا SLI HB در پیکربندیهای دوگانه GTX 1080 استفاده شود. در جدول زیر میتوانید با توجه به نیازهای خود، نوع پل SLI مورد نظر را شناسایی کنید.
با پهنای باند بالای ارائه شده توسط رابط جدید SLI و پلهای جدید SLI HB گیمرها نسبت به نسل قبلی SLI بهمراتب اجرای روانتری را در بازیهای جدید تجربه خواهند کرد. در گراف زیر نمودار FrameTime اجرای بازی Shadow of Mordor را در رزولوشن 11520x2160 مشاهده میکنید.
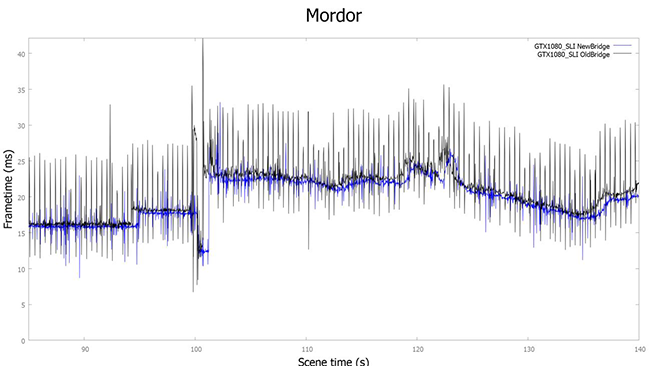
همانطور که ملاحظه میکنید در حالتی که از پل جدید SLI HB استفاده شده است (گراف آبی رنگ) روی هم رفته FrameTime پایینتر و از آن مهمتر spike ها نیز بهمراتب کمتر هستند. این بدان معناست که Frame Rate بالاتر و پایداری این پارامتر نیز بهمراتب بهتر از قبل شده است.
حالتهای جدید پیکربندی Multi-GPU
در مقایسه با نسخههای قبلی DirectX کمپانی مایکروسافت چند تغییر در DirectX 12 جدید ایجاد کرده که عملکرد پیکربندیهای Multi-GPU را نیز تحت تأثیر قرار میدهند. در بالاترین سطح دو انتخاب اساسی برای توسعه دهندگان جهت استفاده از پیکربندیهای Multi-GPU در سخت افزاریهای انویدیا در DirectX 12 وجود دارد: حالت (Multi Display Adapter (MDA و حالت (Linked Display Adapter (LDA.
برای حالت LDA نیز دو شکل متفاوت تعریف شده است: حالت Implicit LDA که NVIDIA برای SLI از آن استفاده میکند و حالت Explicit LDA که در اصل توسعه دهندگان بسیاری از مسئولیتهای GPU را برای دستیابی به یک پیکربندی موفق و با بازدهی بسیار بالا مدیریت میکنند. در واقع هدف از توسعه حالتهای MDA و LDA Explicit این بوده که توسعه دهندگان بازیهای رایانهای کنترل بیشتری بر روی عملکرد GPU داشته باشند.
در جدول زیر خلاصه قابلیتها و ملزومات این 3 حالت را در پردازندههای گرافیکی Nvidia ملاحظه میکنید:

در حالت LDA تمامی حافظههای Frame Buffer کارتهای گرافیک مستقل شرکت کننده در این پیکربندی با یکدیگر مرتبط خواهند بود تا مجموعهای بسیار بزرگ از حافظه در اختیار توسعه دهنده قرار بگیرد (البته در این ارتباط برخی استثنائات وجود دارد). با این حال در صورتی که اطلاعات مورد نیاز یک GPU در حافظه GPU دیگر ذخیره شده باشد ممکن است نوعی افت کارایی پیش آید. در حالت MDA، حافظه هر GPU به صورت اختصاصی برای همان GPU قابل دسترس است و قابلیت دسترسی مستقیم به حافظه GPU های دیگر را ندارد.
حالت LDA برای وضعیتهایی در نظر گرفته شده است که در آن GPU ها دقیقاً شبیه به یکدیگر هستند در حالی که در حالت MDA محدودیتهای بهمراتب کمتری وجود دارد. برای مثال حتی این امکان وجود دارد که کارتهای گرافیک مجزا با تراشههای گرافیکی مجتمع جفت شوند و یا حتی GPU های با مدلهای مختلف و یا حتی با سازندگان مختلف با یکدیگر جفت شوند. ولی در این حالت توسعه دهنده باید با دقت بیشتری تمامی عملیات و دستورالعملهایی را که برای ارتباط میان GPU ها لازم است را مدیریت کند.
در حالت پیشفرض کارت گرافیک GFEFORCE GTX 1080 تنها از حالت دوگانه (i2-Way) پیکربندی SLI پشتیبانی میکند و حالتهای l3-Way و l4-Way پیکربندی SLI از این پس توسط انویدیا توصیه نمیشود. هم زمان با تکامل هر چه بیشتر بازیها بسیار دشوار خواهد بود تا حالتهای 3 و 4 گانه SLI در حالت عملیاتی افزایش کارایی محسوسی برای کاربران عادی و گیمرها به ارمغان بیاورند. برای مثال در بسیاری از بازیها در پیکربندیهای 3 و 4 گانه این CPU است که گلوگاه کارایی میشود و از طرف دیگر بازیهایی که از تکنولوژیهایی استفاده میکنند که استخراج فریم به فریم و البته متقارن آنها بسیار مشکل است نیز روز بهروز در حال افزایش است. البته مدلهای دیگر برای استفاده از پیکربندیهای l3-Way و l4-Way نیز وجود دارد:
- استفاده از حالتهای MDA و LDA Explicit
- 2-Way SLI + dedicated PhysX GPU
Fast Sync
Fast Sync نوع با زمان تأخیر بهمراتب کمتر تکنولوژی قدیمی Vertical Sync (V-SYNC) است که مانع از به اصطلاح tearing یا گسستگی تصویر در هنگام بیشتر شدن نرخ FPS از Refresh Rate نمایشگر میشود.
در تصویر زیر یک طرح کلی خام از چگونگی رندر شدن یک فریم در pipeline تراشههای گرافیکی Nvidia را ملاحظه میکنید:
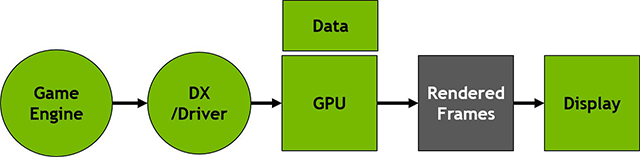
موتور گرافیکی بازی وظیفه تولید فریمها و ارسال آن به DirectX را بر عهده دارند. از دیگر وظایف موتور بازی محاسبه animation time (کد گذاری داخل هر فریم که در نهایت رندر میشود) است. در ادامه سرعت ترسیم و دیگر اطلاعات به درایور و GPU ابلاغ میشوند تا به تصویر رندر شده حقیقی تبدیل شوند. این اطلاعات سپس به حافظه Frame Buffer ارسال شده و در نهایت نیز جهت اسکن به نمایشگر منتقل میشوند.
اما در پردازندههای گرافیکی مبتنی بر معماری Pascal این روال کمی تغییر کرده است.
یک سؤال: در برخی بازیهای کنونی مثل Counter-Strike: Global Offensive که نرخ FPS گاهی اوقات به بیش از صدها فریم در ثانیه میرسد، بهتر است V-SYNC فعال باشد یا غیرفعال؟
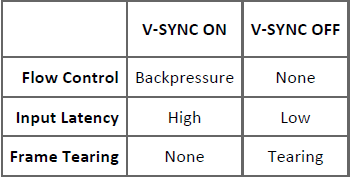
در حالتی که V-SYNC روشن است نرخ FPS هیچ گاه از نرخ Refresh Rate نمایشگر تجاوز نمیکند. این امر در عمل باعث جلوگیری از گسستگی تصویر میشود ولی از طرفی باعث افزایش محسوس زمان تأخیر ورودی میشود.
اما در وضعیتی که V-SYNC خاموش است نرخ FPS به صورت افسار گسیخته افزایش مییابد. در این حالت زمان تأخیر ورودی بسیار پایین است ولی در عمل گسستگی (بریدهبریده شدن) در تصویر خروجی مشاهده میشود.
این دو وضعیت یک چالش بسیار سخت برای گیمرهای کنونی محسوب میشود! و البته انتخاب بین این دو وضعیت نیز در شرایط مختلف همانطور که اشاره شد معایب و مزایای خاص خود را به همراه دارد.
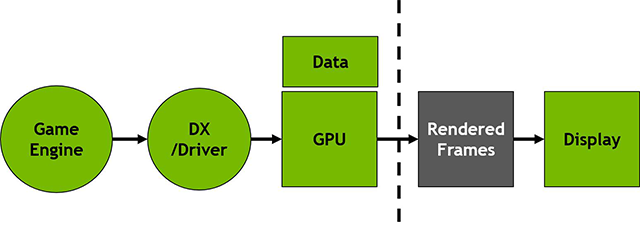
انویدیا با بازنگری در نحوه عملکرد این فرآیند قدیمی در قدم اول در مسیر پردازش تصویر، بخشهای مرتبط با رندر فریم و نمایش تصویر را از یکدیگر جدا کرده است. این امر به بخشهای مرتبط با رندر اجازه میدهد تا بهطور مداوم و با حداکثر سرعت به رندر اطلاعات ارسال شده توسط موتور بازی و درایور بپردازند و این فریمها بتوانند موقتاً در حافظه Frame Buffer ذخیره شوند.
Rendered Frames - FAST SYNC
همانطور که اشاره شد انویدیا در مسیر رندر تصاویر، یخش های مرتبط با رندر و بخشهای مربوط به نمایش تصاویر را از یکدیگر جدا کرده است. این امر اجازه میدهد تا تصویر خروجی با استفاده از راهکارهای جدید مختلف مدیریت شود که این امر مزایای فراوانی برای گیمرها در پی خواهد داشت.
FAST SYNC یکی از اولین کاربردهایی است که این رویکرد جدید همراه خواهد داشت.
با FAST SYNC دیگر کنترل و کندسازی جریان پردازش گرافیکی (flow control) وجود نخواهد داشت، عملکرد موتور گرافیکی همانند وضعیتی است که V-SYNC غیرفعال است و همه اینها به این دلیل است که دیگر مسیر پردازش تصویر، پدیده تجمع فریمها در حافظه Frame Buffer وجود ندارد. زمان تأخیر تقریباً همانند زمانی که V-SYNC غیرفعال است پایین است و از همه بهتر تصویر نیز دیگر گسستگی مشاهده نخواهد شد! چون FAST SYNC انتخاب میکند که کدام یکی از فریمهای رندر شده باید توسط نمایشگر اسکن شود. FAST SYNC به مسیر پردازش تصویر این اجازه را میدهد تا با حداکثر سرعت به پردازش تصاویر بپردازد و تعیین میکند تا کدام فریم برای اسکن به نمایشگر ارسال شود، در حالی که بهطور همزمان همه فریمها حفظ میشوند و تصویر نیز بدون گسستگی در نمایشگر اسکن میشود.
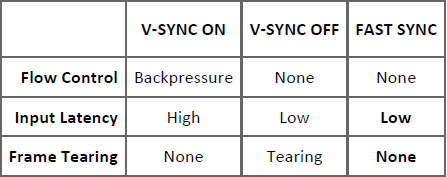
تجربهای که FAST SYNC ارائه میدهد بسته به نرخ FPS از نظر کیفیت و وضوح تصویر همانند وضعیتی است که V-SYNC فعال است. همچنین زمان تأخیر ورودی نیز بسیار پایین و مانند وضعیتی است که V-SYNC خاموش است.
Decoupled Buffers
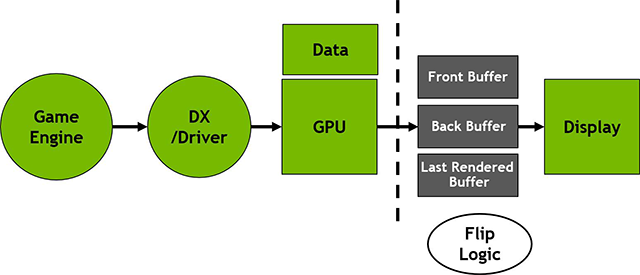
اما شاید برای شما نیز سؤال شده باشد که FAST SYNC چگونه کار میکند؟
تصور کنید 3 ناحیه در حافظه Frame Buffer تعبیه شده است که دارای 3 عملکرد متفاوت میباشند. 2 بخش بافر اول همانند تکنیک double-buffered V-SYNC در GPU های نسل قبل عمل میکنند. باور جلویی (Front Buffer) تصاویری که برای اسکن به نمایشگر فرستاده میشوند را در خود ذخیره میکند. بافر پشتی (Back Buffer) اطلاعاتی را همراه دارد که در حال رندر شدن هستند و تا زمانی که این فرآیند شکل گیری تصاویر به پایان نرسند اجازه اسکن شدن را ندارند. استفاده از V-SYNC مرسوم در گیم های با نرخ FPS بالا اصلاً زمان تأخیر ورودی مناسبی نخواهد داشت چون موتور بازی باید منتظر وقفه ایجاد شده توسط Refresh Rate نمایشگر بماند تا قبل از اینکه فریمهای جدید در Back Buffer بارگذاری شوند، با تلنگر Back Buffer اجازه ارسال اطلاعات به نمایشگر را صادر کند. این روال تمامی مراحل را کند میکند و در عمل Back Buffer را به یک عامل ایجاد زمان تأخیر تبدیل میکند.
FAST SYNC بافر سومی تحت عنوان (Last Rendered Buffer (LRB را همراه خود دارد که وظیفه آن ذخیره تمامی تصاویر رندر شدهای است که در Back Buffer کامل شدهاند. در نتیجه داشتن یک کپی از فریمهایی که اخیراً توسط Back Buffer رندر شده تا زمانی که Front Buffer کار اسکن تصویر را کامل کند در این نقطه Last Rendered Buffer نیز در Front buffer کپی میشود و این روند ادامه مییابد. عملاً و در واقع رونویسی بافر ناکارآمد خواهد بود و در اصل نام این Buffer ها در طی این فرآیند تغییر میکند.
بافری که تصویر را اسکن میکند FB، بافری که به صورت فعال در حین رندر کردن تصاویر است BB و بافری که حاوی تصاویری است که اخیراً رندر شدهاند نیز LRB نامیده میشود. واحد جدید flip logic نیز در معماری Pascal این فرآیند را کنترل و مدیریت میکند. نمونه کاملی از این فرآیند همانند روال زیر خواهد بود:
- Scan from FB
- Render to BB
- When Render completes
- BB becomes LRB
- LRB becomes BB and render continues
- When Render completes
- BB becomes LRB
- LRB becomes BB and render continues
- When Render completes
- BB becomes LRB
- LRB becomes BB and render continues
- When scan completes
- LRB becomes FB
- Start scanning from the new FB
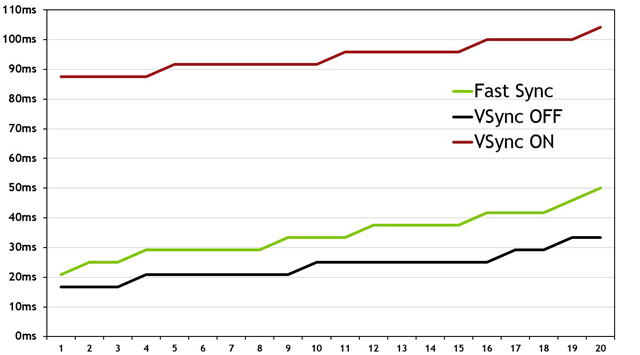
در نمودار بالا تست این قابلیت را در بازی Counter-Strike: Global Offensive ملاحظه میکنید که توسط دوربینهای بسیار پرسرعت تصویربرداری شده است. به روشنی مشخص است که Fast Sync تنها با حدوداً 8ms زمان تأخیر بیشتر نسبت به حالتی که V-SYNC غیرفعال است مانع از گسستگی شدن تصویر شده است! این در حالی است فعال بودن V-SYNC سنتی عملاً بیش از 9 برابر زمان تأخیر ورودی را افزایش داده است.
نکته: Fast Sync بهترین عملکرد را در بازیهای با نرخ FPS بالا مبتنی بر DirectX 9 دارد.
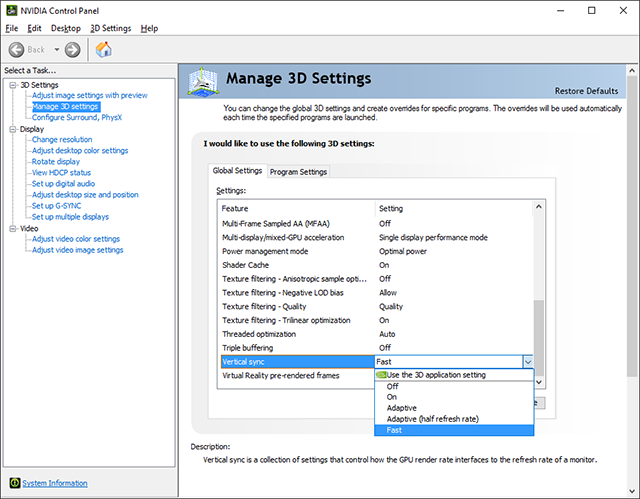
جهت فعال سازی این قابلیت باید در نرم افزار NVIDIA Control Panel و در بخش مربوط به مدیریت تنظیمات سه بعدی (Manage 3D settings) گزینه FAST را برای پارامتر Vertical sync انتخاب کنید. توجه داشته باشید که عملکرد این پارامتر در حال پیش فرض به موتور گرافیکی گیم سپرده شده است.
HDR
نمایشگرهای جدید با محدوده دینامیکی بالا (HDR) یکی از بزرگترین پیشرفتهای 20 سال اخیر در کیفیت پیکسل صفحه نمایش محسوب میشوند. طیف رنگ BT.2020 حداکثر 75% از رنگهای قابل روئیت توسط چشم انسان را پوشش میدهد (33% بیشتر از طیف رنگ sRGB). این یعنی افزایش 2 برابری محدوده رنگها. علاوه بر این نمایشگرهای HDR حداکثر روشنایی بهمراتب بیشتری نسبت به نمایشگرهای نسل قبل دارند (بیش از 1000 nits در نمایشگرهای LCD) و همینطور درخشندگی بهمراتب بیشتر (l>10:000 to 1).
(Standard Dynamic Range Image (SDR

(High Dynamic Range Image (HDR 1000

با محدوده بیشتر روشنایی و اشباع رنگ، محتوای HDR نمایش واقعگرایانهتری از جهان واقعی خواهند داشت: رنگهای مشکی عمیقتر و رنگهای سفید روشنتر از قبل به نظر میرسند. تغییرات ایجاد شده در تولید رنگ باعث ایجاد تصاویر واقعیتر میشود که حقیقتاً حیرت انگیز است. کاربران سرانجام میتوانند طیف رنگهای قرمز و نارنجی را در آتش و یا انفجار مشاهده کنند. همچنین به خاطر درخشندگی (Contrast) بیشتر در نمایشگرهای HDR کاربران میتوانند جزئیات بیشتری را در نقاط کاملاً تاریک و یا با نور بسیار زیاد مشاهده کنند.

کارتهای گرافیکی مبتنی بر معماری Pascal همانند نمونههای مشابه نسل قبل (Maxwell) از تمامی نمایشگرهای HDR پشتیبانی میکنند و به لطف کنترلر نمایشگر تعبیه شده در آنها از قابلیتهای 12b color، طیف رنگ گسترده (BT.2020،(SMPTE 2084 (Perceptual Quantization و HDMI 2.0b 10/12b برای 4K HDR نیز برخوردار هستند؛ اما در معماری Pascal برخی قابلیتهای جدید به این مجموعه اضافه شده است:
- 4K@60 10/12b HEVC Decode (برای ویدئوهای HDR)
- 4K@60 10b HEVC Encode (برای ضبط و یا استریم ویدئوهای HDR)
- DP1.4-Ready HDR Metadata Transport (برای اتصال به نمایشگرهای HDR با رابط Display Port)

تلویزیونهای HDR در حال حاضر موجود هستند و قابلیتهایی که به آن اشاره شد این امکان را فراهم میسازند تا کاربران به واسطه دستگاه HDR Gamestream که در آینده نزدیک به بازار عرضه خواهد شد بدون اتصال مستقیم PC خود به تلویزیون بازیهای HDR را بر روی این نمایشگرها اجرا و از آنها لذت ببرند.
همچنین انویدیا در حال کار با توسعه دهندگان است تا HDR را به بازیهای رایانهای نیز ببرند. انویدیا با فراهم کردن API، درایورهای لازم و همچنین راهنمایی لازم، توسعه دهندگان را پشتیبانی میکند تا بتوانند تصاویر رندر شده HDR سازگار با این نوع نمایشگرها را با بهترین کیفیت و وضوح ممکن ارائه کنند. بازیهای با محتوای HDR مثل Obduction, The Witness, Lawbreakers, Rise of the Tomb Raider, Paragon, The Talos Principle و Shadow Warrior 2 در حال حاضر عرضه شده و یا در آینده نزدیک عرضه خواهند شد.

Video and Display
پردازندههای گرافیکی مبتنی بر معماری Pascal با پشتیبانی از گواهی نامه (PlayReady 3.0 (SL3000 و رمزگشایی HEVC با استفاده از شتاب دهندههای سخت افزاری برای اولین بار قابلیت مشاهده ویدئوهای 4K premium را توسط PC فراهم کردهاند. در ماههای آینده کاربران مجهز به پردازندههای گرافیکی Pascal این امکان را خواهند داشت تا در Netflix و یا دیگر ارائه دهندگان محتوای باکیفیت، با رزولوشن 4K محتواهای مختلف را استریم و مشاهده کنند.

به لطف برخورداری GeForce GTX 1080 از گواهی نامه Display Port 1.2 و به همراه داشتن قابلیتهای DP 1.3/1.4 پشتیبانی از نمایشگرهای با رزولوشنهای 4K در 120Hzا، 5K در 60Hz و 8K در 60Hz (به واسطه دو کابل مجزا) فراهم شده است.
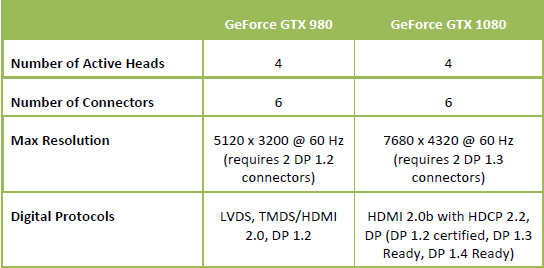
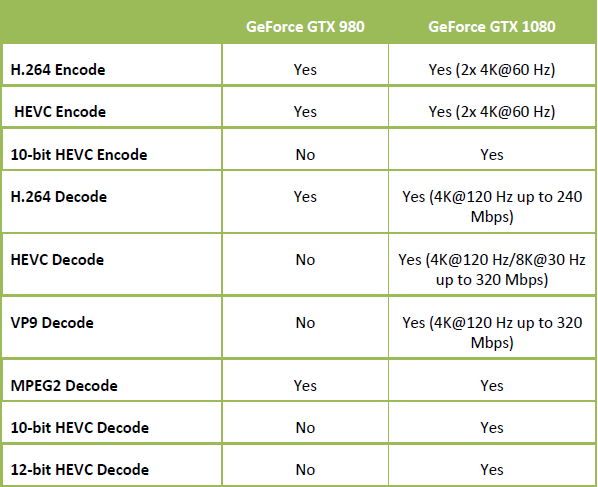
جدول زیر به صورت خلاصه قابلیتها و ویژگیهای خروجی تصویر Geforce GTX 1080 را در مقایسه با Geforce GTX 980 نشان میدهد:
مدل Founders Edition کارت گرافیک Geforce GTX 1080 دارای 3 خروجی تصویر Display Port، یک خروجی تصویر HDMI 2.0b و یک پورت Dual Link DVI است که قادر به ارائه 4 تصویر به صورت همزمان هستند.
در جدول زیر نیز به صورت خلاصه قابلیتهای Geforce GTX 1080 را در رمزگذاری و رمزگشایی Codec های مختلف ویدئویی در مقایسه با Geforce GTX 980 مشاهده میکنید:
VRWorks Graphics
گیمینگ واقعیت مجازی زمان پاسخ دهی بسیار پایین و از آن مهمتر نرخ Frame Rate بالایی را برای داشتن تجربهای دل چسب و همه جانبه توسط کاربران طلب میکند. این در حالی است که کیفیت بازیهای اخیر مبتنی بر VR خوب به نظر میرسد ولی هنوز به مرحلهای نرسیده است که از نظر کیفیت با بازیهای مدرن غیر VR برابری کنند. یکی از مهمترین دلایل این امر الزامات مربوط به نرخ Frame Rate بالا است که هم اکنون پردازندههای گرافیکی با قدرت کم توانایی ارائه آن را باکیفیت بالا و همراه با افکتهای واقعگرایانه ندارند.

بهمنظور همسان سازی کیفیت گرافیکی بازیهای مبتنی بر VR و غیر VR، انویدیا در پردازندههای گرافیکی مبتنی بر معماری Pascal چندین تکنولوژی جدید جهت افزایش کارایی رندر گرافیکی در کاربردهای VR توسعه داده است. این تکنولوژیها در نهایت سبب شدهاند تا Geforce GTX 1080 در کاربردهای VR بیش از دو برابر سریعتر از Geforce TITAN X باشد. با این افزایش کارایی در پردازندههای گرافیکی مبتنی بر معماری Pascal از این پس توسعه دهندگان بازیهای VR میتوانند کیفیت گرافیکی نظیر بازیهای مدرن غیر VR را برای محتوای گرافیکی ساخت خود فراهم کنند.

VRWorks Audio
تکنولوژیهای شنیداری در گیم و واقعیت مجازی مرسوم کنونی، موقعیت دقیقی از منبع صدا را در یک محیط مجازی ارائه میدهند. برای مثال اگر در یک بازی ژانر شوتر، دشمن از سمت راست شما به طرفتان شلیک کند شما نیز در عمل همین حس را خواهد داشت. دلیل این امر پخش شدن بلندتر صدای شلیک از بلندگوی سمت راست اسپیکر شما نسبت به اسپیکر سمت چپ است و البته این صدا کمی زودتر نیز از بلندگوی سمت راست شنیده میشود. این شبیه سازی در تقدم رسیدن و تقدم انرژی اولین موج صدا برای رسیدن به شنونده را اصطلاحاً Direct Sound مینامند. تفاوتها در انرژی و تقدم رسیدن Direct Sound به هر گوش شنونده نیز Binaural Effects نامیده میشود.
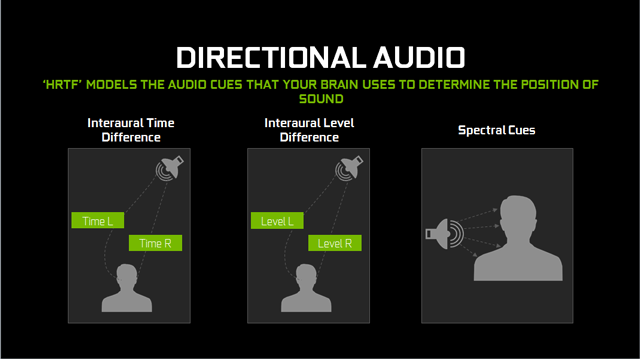
اما در جهان واقعی صداها در جهات مختلفی پخش میشوند و ممکن است به صورت مستقیم به گوش شنونده نرسند. بعضی از این صداها ممکن است در اثر انعکاس برخورد موج صدا به سطوح مختلف به گوش شنونده برسند. به این گونه از امواج، صدای غیرمستقیم، صدای منعکس شده و یا طنین صدا اطلاق میشود. نوع صدای غیرمستقیم به اندازه، شکل و خواص متریال محیط اطراف آن بستگی دارد. برای مثال، وقتی که در حمام کوچک با دیوار کاشی شده و کفپوش قدم میزنید، صدای قدم برداشتن شما بلندتر و با پژواک بیشتری به گوش میرسد تا زمانی که در همان محیط ولی با دیوارهای گچی و کف پوشیده شده با فرش قدم میزنید. در واقع متریال مختلف در انعکاس صدا در جهات مختلف نقش بسیار مهمی دارند. بعضی متریال مانند کاشی و کفپوشها باعث انعکاس حجم زیادی از انرژی صوتی میشوند و بعضی از متریال مانند موکت و فرش حجم اعظمی از انرژی صوتی را جذب خود میکنند.
NVIDIA VRWorks Audio از تکنیک Ray tracing که در گرافیک کامپیوتری جهت رندر و ترسیم تصاویر استفاده میشود برای ردیابی مسیر انتشار اصوات در یک صحنه مجازی استفاده میکند. VRWorks Audio انرژی اصوات منتشر شده را از طریق محیط اطراف شبیه سازی میکند. برای این منظور یک موج برای ردیابی مسیرهای مستقیم و یا غیرمستقیم بین منبع اصوات و شنونده ارسال میشود. وقتی این امواج به سطوح مختلف محیط آن صحنه برخورد میکنند ممکن است جذب شده، منعکس شده و یا با توجه به زاویه برخورد خود پراکنده شوند و همانطور که اشاره شد جنس متریال سطوح نیز در این امر دخیل است.

VRWorks Audio در واقع Binaural Effects را در Direct sound ایجاد میکنند که قبلاً نیز گیمرها آن را تجربه کردهاند؛ اما وجه تمایز این تکنولوژی با موارد مشابه پشتیبانی آن از جلوههای صوتی انتشار غیرمستقیم امواج صوتی است که به شنونده اطلاعات مربوط به ابعاد و ساختار فضایی که در آن حضور دارد را نیز میدهد.
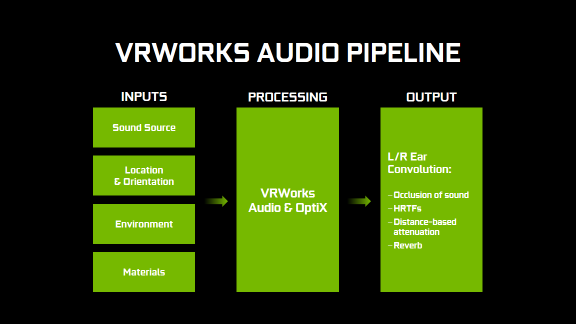
تکنولوژی VRWorks Audio از همان موتور NVIDIA OptiX ray tracing engine استفاده میکند که نرم افزارهای مبتنی بر تکنیک Ray tracing برای پردازش اطلاعات بهره میبرند. موتور OptiX در بازیهای رایانهای سازگار با آن میتواند باعث افزایش سرعت بسیاری از عملیات مثل پردازش دقیق Ambient Occlusion و نورپردازی شود. با تکنولوژی VRWorks Audio، گیمرهای واقعیت مجازی صدای 3 بعدی فراگیرتری را تجربه خواهند کرد که در کنار کیفیت بالای گرافیکی ارائه شده توسط پردازندههای گرافیکی مبتنی بر معماری Pascal، آنها را در محیط مجازی گیم ها غرق خواهد کرد!
PhysX for VR Touch & Environmental Simulation
مدل سازی واقعگرایانه تعاملات لمسی و حرکات در محیط پیرامونی برای ارائه تجربه کاملی از واقعیت مجازی دو امر حیاتی محسوب میشوند. امروزه واقعیت مجازی نوعی تعامل قابل لمس از محیط ارائه میکنند که بر اساس ترکیبی از ردیابی موقعیتی، کنترل دست و تکنولوژیهای حسی و لمسی کار میکنند. تکنولوژی NVIDIA’s PhysX Constraint Solver زمانی که کنترلر دست با یک جسم مجازی تعامل پیدا میکند را شناسایی کرده و موتور بازی را قادر میسازد تا در نهایت پاسخ فیزیکی بصری و لمسی دقیقی را در خروجی ارائه دهد.

تکنولوژی PhysX همچنین رفتار فیزیکی دنیای مجازی اطراف شما را طوری مدل سازی میکند که همه فعل و انفعالات مثل انفجار و یا پاشش آب زمانی که یک دست وارد آب میشود دقیق و همانند فعل و انفعالات دنیای واقعی به نظر برسد.

منبع: nVIDIA Whitepapers

")




















نظر خود را اضافه کنید.
برای ارسال نظر وارد شوید
ارسال نظر بدون عضویت در سایت